
前言
上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布。不清楚的童鞋可以点击参考。
作为调优系列的文章,数据库的索引肯定是不能少的了,所以本篇我们就开始分析这块内容,关于索引的基础知识就不打算深入分析了,网上一搜一片片的,本篇更侧重的是一些实战项内容展示,希望通过本篇文章各位看官能在真正的场景中找到合适的解决方法足以。
对于索引的使用,我希望的是遇到问题找到合适的解决方法就可以,切勿乱用!!!
本篇在分析出索引的优越性的同时也将负面影响展现出来。
技术准备
数据库版本为SQL Server2012,前几篇文章用的是SQL Server2008RT,内容区别不大,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks
相信了解SQL Server的朋友,对这两个库都不会太陌生。
概念理解
所谓的索引同SQL Server中的其它类型的数据页一样,也是固定的8KB(8192字节),存储方式同为B-Tree结构,索引B树中的每一页称为一个索引节点。B树顶端节点为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引统称为中间级。
算了,描述起来太麻烦,联机丛书上截个图直观的展示结构:
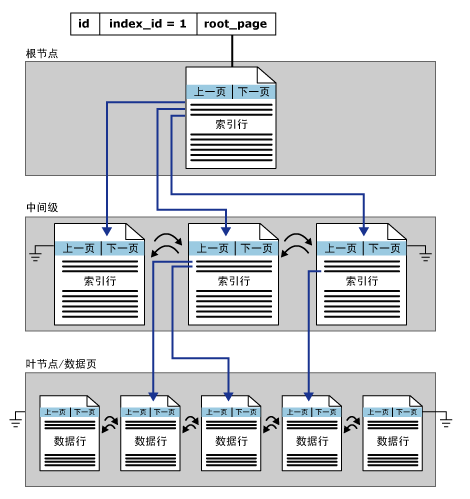
上面的图直观的展示出B-Tree结构的方式,基本和数据页的结构类似,这里有一点需要提醒下,就是聚集索引的最底层的叶子节点存储的为实际的数据页。就这一点为数据的快速获取可谓提供了一个超快方式,也是我们调优中必须要使用的,后续文章中分析。
再来看一下非聚集索引。

非聚集索引和聚集索引相比,同样以B-Tree的结构存储,但是在存储的内容上有着显著的区别:
- 基础表的数据行不按非聚集索引键的顺序排序和存储
- 非聚集索引的叶层是由索引页而不是由数据组成
由于上面的几种特性中,很明显的获取数据最快的方式是通过聚集索引,因为它叶子节点就是数据页,同样叶子节点的数据页物理顺序也是按照聚集索引的结构顺序进行存储,这也就造成了一个数据表只能存在一个聚集索引,并且聚集索引所占据的磁盘空间要远远小于非聚集索引。
而对于非聚集索引的叶子节点存储的是索引行,获取数据的话必须通过索引行所记录的数据页的地址(聚集索引键或者堆表的RID),这一特性也就是造就了,一张数据表可以有多个非聚集聚集索引,并且需要自己独立的存储空间。
两种索引设计的初衷都是为了便于快速的获取到数据页,提高查询性能。这就好比一本书需要加上目录一个道理。
关于索引的知识很多,基础的内容不作太多介绍,不了解的可以自行查阅资料,网上N多。
下面主要介绍一下使用技巧和注意事项,我相信这也是朋友们最关注的。
一、聚集索引的选择
所有的利用索引提升查询性能方式中,首当其中的就是聚集索引,它速度快是因为B-Tree这种优越的存储算法,B-Tree作为一个平衡分叉树的数据结构,是市面上所有的关系型数据库所采用的方式,有兴趣的同学可以深入研究一下此种算法。
来看一下聚集索引,因为在一张表中只能存在一个,并且主要经过聚集索引查找在叶节点就可以获取到数据内容,所以SQL Server数据库系统也在尽力的为聚集索引的存在提供便利。
举个例子:
USE [TestDB]
GO
CREATE TABLE [dbo].[TestTable](
[A] [int] PRIMARY KEY NOT NULL,
[B] [varchar](20) NULL
)
GO
我们创建一张测试表,一般采取的最佳设计是在这张表上添加一个主键。
主键的概念,我相信几乎了解点数据库的童鞋就不陌生,两大基本特性:不重复、非空。
好了,仅仅这两点就被利用,不重复所带来的含义就是选择性高,非空更能带来数据的稠密度高,因此,SQL Server就痛快的将聚集索引选在了主键列上,并且这种方式在数据库中起了一个高雅的名字:主键索引。
所以当我们创建完这张表的时候,SQL Server默认就将该表的聚集索引建立好了。
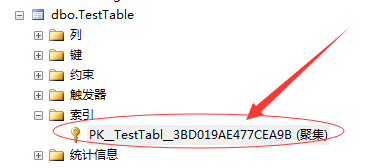
为了避免名称的重复,SQL Server默认给名称加了一个GUID的字段。真可谓用心了。
当然,正规的方式使我们自己指定这个名称,脚本如下:
CREATE TABLE [TestTable3]
(
[A] [int] NOT NULL,
[B] [varchar](20) NULL
CONSTRAINT PK_Index PRIMARY KEY([A])
);
GO
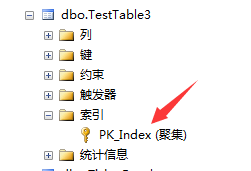
看上去优雅多了。
其实,SQL Server这种默认的方式最主要的目的就是为了最大限度的利用好聚集索引,因为我们知道聚集索引所带来的好处,并且它还为非聚集索引的形成创造了基础条件:非聚集索引的叶子节点就是聚集索引的键值码。
所以基于此,我们以后设计表的时候,也不要辜负了SQL Server的用心,将每张表都应该有一个聚集索引。
我见过很多人设计出来的表就是赤裸裸的堆表。而这不是严重的,严重的是很多不明所以的在堆表上加上了非聚集索引,这在大并发的场景中就是一个典型的死锁环境,文章后面会复现该场景。
当然,这种方式不是一个最优的一种方式,因为我们知道我们在设计表的时候,主键大部分情况下为无意义的键,也就说很多的情况在查询的时候是不会作为 筛选条件的,并且它所覆盖的范围也仅限于主键列。所以最优的设计是采用联合主键或者自定义聚集索引列。当然了,SQL Server上面这种设计的初衷大部分是考虑了小白的建表方式,权衡了利弊选出的一种折中方式,如无特别需求,默认的这种建立聚集索引的方式基本能满足业务场景。
接着我们分析下非聚集索引
二、非聚集索引的选择
经过文章前面的分析,我们可以了解到聚集索引所带来的好处,但是它也有着最大的自身限制性:一张表只能存在一个聚集索引。
为了更多的使用索引,SQL Server又引入了非聚集索引,并且单张表的非聚集索引项可以存在好多个,因此足以让我们领略索引带来的性能提升。
上面,我们知道在一张表指定主键的时候,SQL Server默认就将聚集索引给创建好了,但是对于非聚集索引的创建,SQL Server默认是不会帮助建立的,需要我们手动建立,因为它也不知道你的非聚集索引创建到那一列上更合适。
但是,通常有一个最佳实践就是,作为关系性数据为了应付复杂的业务实体,采用的设计结构一般都是采用一对一、一对多、多对多的设计思路,而这种设计结构就形成了主外键的关系,我们知道主键SQL Server会自动的创建聚集索引,索引在外键中推荐的方式是手动创建非聚集索引,目的是为了加快表之间的映射关系。
但是,非聚集索引因为其存储结构的特别性(叶节点存储的非数据页),影响了它读取数据的效率,并且更多时候我们要获取的是一部分数据而非一条数据。
在获取的一部分数据为非聚集索引所覆盖那么利用非聚集索引是高效的,如果获取的数据非索引所覆盖,也就是通过聚集索引查找的时候还需要引入额外的书签查找,这种状态效率是非常低的,因为我们知道对于B-Tree结构下的书签查找是:随机IO,随机IO所带来的性能消耗是非常大的,为此SQL Server会放弃这种方式,直接通过表扫描(Table seek)或者聚集索引扫描(Index Seek)获取的数据更直接。
上面的这部分内容,我在前面的第一篇文章就有介绍,可以点击查看。
描述起来太麻烦,来个例子解释下:
SELECT OrderID,CustomerID,OrderDate FROM Orders ORDER BY OrderDate
很简单的查询,来看一下执行计划
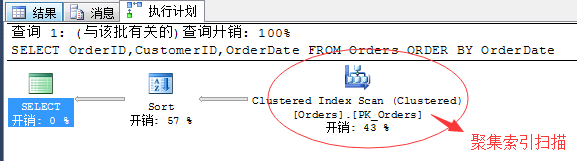
因为该表上存在一个主键,所以这里采用了聚集索引扫描(Index Scan),如果没有聚集索引,这里肯定就是表扫描了。
下面我们利用一个Hint提示来查看一下SQL Server利用非聚集索引的过程。
这里我们用Fast N Hint提示,这个提示很简单就是告诉SQL Server快速的先获取出前N行数据,别的数据都靠后…把前N行的数据获取效率提至最高(记住:这个提示最佳的应用场景就是分页查询,很多业务系统都有分页显示,加上此Hint会让数据库最快的获取出前多少条数据)
我们后续的文章会详细分析各种Hint的用处。
继续分析,我想快速获取到前1行数据,脚本如下:
SELECT OrderID,CustomerID,OrderDate FROM Orders ORDER BY OrderDate OPTION(FAST 1)
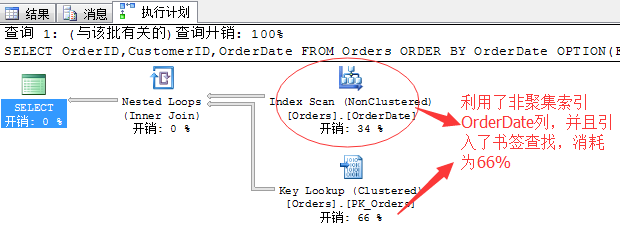
为了快速获取到一行数据,SQL Server更改了执行计划,采用了非聚集索引来扫描,并且为了获取出其它列的数据不得不引进一个书签查找(Key Lookup),从上面我们可以看到书签查找的消耗高达66%。
我们接着分析,我想获取前十行的数据,脚本如下:
SELECT OrderID,CustomerID,OrderDate FROM Orders ORDER BY OrderDate OPTION(FAST 10)
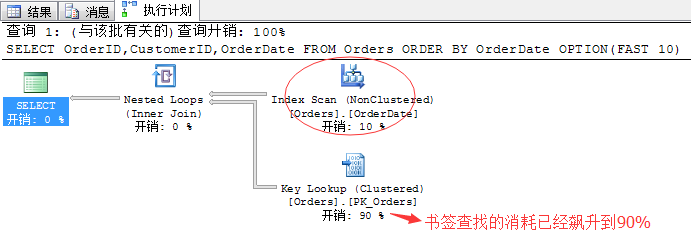
当我们要获取十行的时候,书签查找的消耗已经开始飙升,上面已经飙升到了90%….原因很简单,就是我文章前面分析的这里是随机IO…
虽然书签查找影响效率,但是我们查找的数据只是很少的一部分,所以这里SQL Server认为利用非聚集索引+书签查找获取数据还是一种最优方式。
我们接着分析,我想快速获取二十行数据,脚本如下
SELECT OrderID,CustomerID,OrderDate FROM Orders ORDER BY OrderDate OPTION(FAST 20)

到此,SQL Server已经果断的放弃了非聚集索引+书签查找这种方式。采用了聚集索引扫描这种更低廉的方式。
经过我的测试,我找到了SQL Server认为这个聚集索引有效的数值范围:
SELECT OrderID,CustomerID,OrderDate FROM Orders ORDER BY OrderDate OPTION(FAST 15) SELECT OrderID,CustomerID,OrderDate FROM Orders ORDER BY OrderDate OPTION(FAST 16)
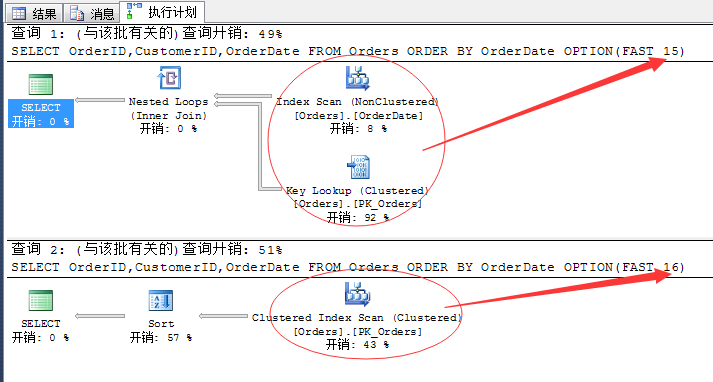
这个判别的阀值是15行,一旦超过了15行数据,SQL Server就会放弃非聚集索引了。
我们从这个过程中可以分析出非聚集索引的有效范围:15(有效行数)/1660(总行数)=0.009638,也就是9%的这么一个量,当然,这个值非固定值,取决于多种因素,比如行类型、内容分布、硬件环境等吧。
但是,通过这个值我想告诉你的是:非聚集索引的有效性其实范围很窄,因为其覆盖范围小,这就导致了很多童鞋建立好了非聚集索引了,但是在真正执行的时候基本是没有用。
这里再多谈点,还有很多人误认为神马非聚集索引选INT类型比选Varchar类型好,更有甚者上次看到群里有人为了把电话号码也存储成INT….目的就是为了查找快云云…
关于这些观点,其实都是很浅层的理解…索引列的选择最好是整型不错,但是也好区分好列内容分布,选择的标准只有一个:最大限度的提升SQL Server的可选择性。
举个极端点的例子:将性别列加上非聚集索引:选择性只有50%…….本来非聚集索引覆盖范围就小,这种索引基本上就是无用…
另外,还要注意索引的顺序问题,比如:两列值:姓、名字,设计索引的时候请将姓放在前面,然后是名字…这就好比你查找通讯录一般最先区分姓,然后在找名字一样….
好吧…一谈就谈多了,回归咱们的内容。
上面的非聚集索引带来的随机IO问题,SQL Server从2005版本也给出了解决方法:包含性的列索引
其实很简单,就是在存储非聚集索引的时候将要获取的数据页包含进叶子节点。
就是为了模仿聚集索引的方式,将非聚集索引的叶子节点也存放进数据页信息,当然,因为物理数据页只有一份,所以非聚集索引只能再拷贝一份自己存储了,这样在查找非聚集索引的时候就可以直接获取数据了。
代码如下:
USE [Northwind]
GO
CREATE NONCLUSTERED INDEX [OrderDateINDEX] ON [dbo].[Orders]
(
[OrderDate] ASC
)
INCLUDE
(
[OrderID],
[CustomerID]
) WITH (ONLINE = ON)
GO
这样的话,在查找这列的时候就都会采用此非聚集索引了。并且避免了随机IO(书签查找)的存在,降低了IO值,提升了性能。
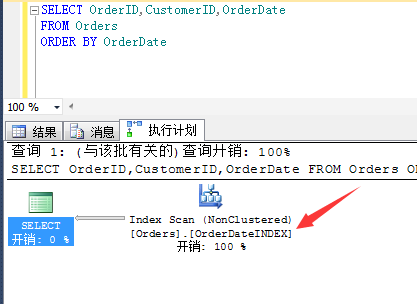
当然,在大部分的业务系统中,利用非聚集索引获取的数据量还是比较少的,大部分是一条展示明细页面,这样的话非聚集索引的有利面就充分显现了。
所以针对OLTP业务系统而言,要学会利用好非聚集索引。
当然,凡事有利有弊,也不能过多的创建非聚集索引,如果利用过多的索引这就好比将一张表的各个列数据拷贝了N份重新存储,占用空间不说,最主要的是 SQL Server在新添加数据的时候需要维护各个非聚集索引,这会导致数据的插入速度减慢,还会造成更多的索引碎片,增加读取IO。
下面,我们来重现下文章前面提到的死锁现象,这些问题纯粹是设计不到位导致。
关于此问题高兄在以前的文章中就有介绍,这里我借用以下它的脚本来重现下,点击此可以连接到高兄的那篇文章。
脚本如下:
create table testklup ( clskey int not null, nlskey int not null, cont1 int not null, cont2 char(3000) ) create unique clustered index inx_cls on testklup(clskey) create unique nonclustered index inx_nlcs on testklup(nlskey) include(cont1) insert into testklup select 1,1,100,'aaa' insert into testklup select 2,2,200,'bbb' insert into testklup select 3,3,300,'ccc'
开启一个线程进行查询修改
----模拟高频update操作 declare @i int set @i=100 while 1=1 begin update testklup set cont1=@i where clskey=1 set @i=@i+1 end
另外同样一个线程进行查询操作
----模拟高频select操作
declare @cont2 char(3000)
while 1=1
begin
select @cont2=cont2 from testklup where nlskey=1
end
本来两个操作,一个要修改,一个要查询,SQL Server会自动很好的维护好两者秩序,不会发生死锁的情况,但是…但是我们在上面创建了一个包含性的非聚集索引,将Cont1列拷贝进入了非聚集 索引,这样修改操作就需要维护非聚集索引列,而这时候我们有利用非聚集索引进行查询,两者恰巧发生在同一张表的两个不同的键值上,这就造成了一次死锁的发 生。
我们开启Profile来捕捉此死锁的发生。

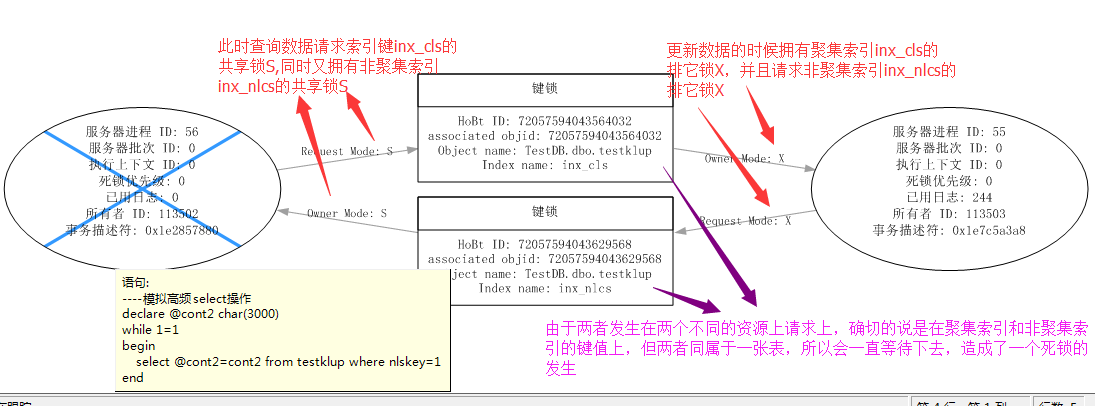
其实,对于这种问题好几种解决方式,因为我们这知道这个问题的罪魁祸首就是我们创建的非聚集索引不恰当,使得查询和修改发生在两个同一张表的不同键值上。
所以一种解决方式就是,直接将这个聚集索引去掉。这样就不会产生额外的键锁的存在。
另一种方式就是讲我们的非聚集索引把cont2列也包含进去,脚本如下
CREATE NONCLUSTERED INDEX [inx_nlskey_incont2] ON [dbo].[testklup] ([nlskey] ASC) INCLUDE ( [cont2])
当然,也可以提高隔离级别或者降低隔离级别,但这不是推荐的方法,原因很简单:降低隔离级别会脏读,提高隔离级别会影响并发量。
希望各位看官在设计数据库的时候不要发生此类悲剧。尤其高并发的情况下,一定要谨慎,再谨慎的进行。
当然,这里也要捎带提醒一下:不要手里拿着锤子,眼里看什么都是钉子!!切勿过度设计。
还是那句话,合适的场景采取合适的方案,一切不能武断,更不能轻易听信于别人,要以实践方能出真理。
索引的知识实在是太广泛….稍写点东西就够篇幅了….先到此吧…后续我再补充一部分关于索引的内容。
我们要及时的维护好索引,及时的重建、碎片整理、删除无用索引等操作,包括创建索引的一系列注意项等。
关于此块内容下一篇文章介绍吧。
关于调优内容太广泛,我们放在以后的篇幅中介绍,有兴趣的可以提前关注
三、考察问题
在文章的最后,晒一个前几天在书中看到的一个比较有意思的逻辑,这里共享下供院友们玩味,也考察下对T-SQL语句的逻辑能力,这道题可以作为一道面试题,不算太难,但是完全能测试出对T-SQL编程能力的高低。
问题内容如下:
--创建一个回话信息记录表
CREATE TABLE dbo.Sessions
(
keycol INT NOT NULL IDENTITY,
app VARCHAR(10) NOT NULL,
usr VARCHAR(10) NOT NULL,
host VARCHAR(10) not null,
starttime DATETIME not null,
endtime DATETIME not null,
CONSTRAINT PK_Sessions PRIMARY KEY(keycol),
CHECK(endtime>starttime)
);
GO
--插入部分测试数据
INSERT INTO DBO.Sessions
VALUES('app1','user1','host1','20030212 08:30','20030212 10:30');
INSERT INTO DBO.Sessions
VALUES('app1','user2','host1','20030212 09:30','20030212 11:30');
INSERT INTO DBO.Sessions
VALUES('app1','user3','host2','20030212 09:31','20030212 11:20');
INSERT INTO DBO.Sessions
VALUES('app1','user4','host2','20030212 11:30','20030212 12:30');
INSERT INTO DBO.Sessions
VALUES('app1','user5','host3','20030212 11:35','20030212 12:35');
INSERT INTO DBO.Sessions
VALUES('app2','user6','host3','20030212 08:30','20030212 10:30');
INSERT INTO DBO.Sessions
VALUES('app2','user7','host3','20030212 08:30','20030212 10:30');
INSERT INTO DBO.Sessions
VALUES('app2','user8','host3','20030212 08:30','20030212 10:30');
就一张表,要求获取出:查询出每个应用程序的最大并发数….
问题不是很难,想测试下能力的可以试试…..再重申下,一定好审好题再做,可以将答案给我留言。