
技术准备
数据库版本为SQL Server2012,前几篇文章用的是SQL Server2008RT,内容区别不大,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
一、创建索引
当我们要开始对表进行索引的创建的时候,首先明确的是,一张表内只能创建一个聚集索引,最多可以创建最多249个非聚集索引(SQL Server2005),在SQL Server2008以后聚集索引数提升至999个,上一篇文章我们知道对于聚集索引项一般要创建上,而非聚集索引项要根据日常的T-SQL语句进行选择。
关于索引的选择是一个很考验调优能力的事情,大部分的情况下优质的索引新建全靠经验而论,有兴趣的可以点击查阅我前面的一系列关于分析查询计划的文章,掌握住里面的精髓才能有的放矢。
当然,小白级别的也可以参照如下方法尝试进行创建:
由于SQL Server有着自己的一套调优技巧,所以在我们每次运行的T-SQL语句应该怎样优化,SQL Server是了如指掌的,所以它会将缺失的索引项进行记录,用于提示使用者,尝试去建立这些索引。
主要记录在以下几个DMV中
sys.dm_db_missing_index_details sys.dm_db_missing_index_groups sys.dm_db_missing_index_group_stats sys.dm_db_missing_index_columns(index_handle) sys.dm_db_missing_index_details
--新建表,建立主键,形成聚集索引
CREATE TABLE BigTable
(
[KEY] INT,
DATA INT,
PAD CHAR(200),
CONSTRAINT [PK1] PRIMARY KEY ([KEY])
)
GO
--批量插入测试数据250000行
SET NOCOUNT ON
DECLARE @i INT
BEGIN TRAN
SET @i=0
WHILE @i<250000
BEGIN
INSERT BigTable VALUES(@i,@i,NULL)
SET @i=@i+1
IF @i%1000=0
BEGIN
COMMIT TRAN
BEGIN TRAN
END
END
COMMIT TRAN
GO
SELECT [KEY],[DATA] FROM BigTable WHERE DATA<1000 GO
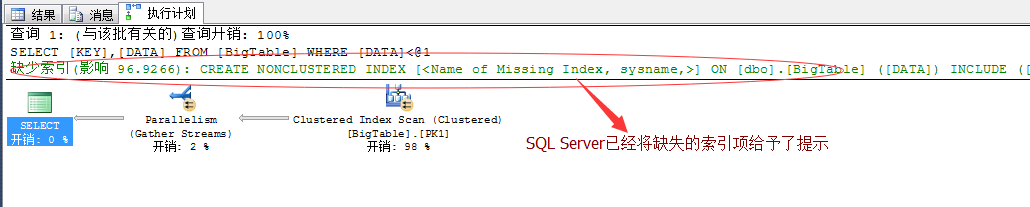
在这个简单的查询脚本中,SQL Server已经提示了我们需要创建的索引项。我们可以右键,直接生成创建脚本
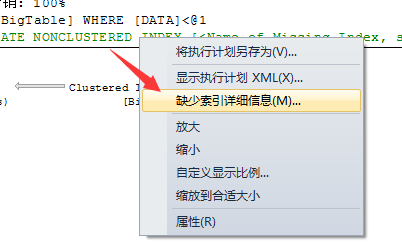

SQL Server已经提示我们要创建的索引项内容了,穿件一个非聚集索引在列DATA上,并且INCLUDE列KEY,并且经创建完这个索引后的提升值都给计算出来了。
以上这种方式,在我们调优的时候是经常使用的,在我们拿到需要优化的语句后,直接执行就可以看到一部分需要调整的信息了。
但是,大部分的T-SQL语句不允许我们进行这样的优化流程,甚至有时候是已经存在的系统。所以,我们下手的方式只能绕道了,幸好SQL Server为我们记录下了这些缺失索引项的信息,就存在我上面提到的几个DMV中。我们来查看下:
SELECT migs.group_handle, mid.* FROM sys.dm_db_missing_index_group_stats AS migs INNER JOIN sys.dm_db_missing_index_groups AS mig ON (migs.group_handle = mig.index_group_handle) INNER JOIN sys.dm_db_missing_index_details AS mid ON (mig.index_handle = mid.index_handle) WHERE migs.group_handle = 2

所以,大部分情况下,通过查看以上语句基本能确认到需要创建的索引项有哪些。
提示:但是,这里的DMV信息只是记录自上次SQL Server启动以后的信息项,也就是说每次重启之后这部分信息就丢失了,所以对于生产系统,建议确保运行了一段周期之后再进行查看。
知道了应该创建什么样的索引,下一步就是创建索引了,来看创建索引的脚本
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [ ,...n ] ) ]
[ ON { partition_scheme_name ( column_name )
| filegroup_name
| default
}
]
[ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ]
当然,如果不熟悉脚本的方式,SQL Server也默认给提供了图形化操作界面,傻瓜式操作

这里我们重点分析几点注意事项。
- UNIQUE:
该关键字指定索引项为唯一值,也就是非重复值,在实际应用中非常的有用,应为唯一就意味着这个索引的高选择性,也就意味着当前索引的可用性高低。
前面文章已经分析了SQL Server会默认的在主键列上创建聚集索引,也是利用了主键的非空和唯一性特点。
当然,这里也提示下聚集索引要求的就是唯一性,如果当前列确实存在重复值,那在创建聚集索引的时候SQL Server会默认的在当前列上加上一个唯一标识符(uniqueifiter)在内部来保证索引的唯一性。但这个时候就不需要显式的指定UNIQUE了,否则会报如下错误:
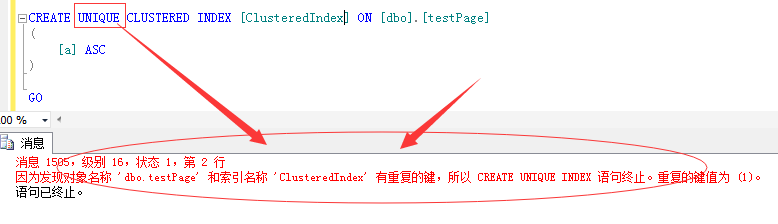
- CLUSTERED|NONCLUSTERED:
这个就是指定创建的索引为聚集还是非聚集索引。
关于它,这里有几点需要注意,因为非聚集索引的叶子节点存储的就是聚集索引键值,所以在创建顺序上要保证优先创建聚集索引,而后再创建非聚集索引,保证有足够的存储空间来存放非聚集索引。
在我们重新创建聚集索引的时候,SQL Server会默认的重新生成全部非聚集索引,如果表数据量特别大,这个过程会很漫长,如果不指定ONLINE的话,这个过程会是锁定索引B-Teee的,这就意味着是阻塞的,业务就要停下来等待完成操作,切记不要将此事发生在生产机上。
当然,以上问题是可以避免的。
- index_name:索引的名字。
- column :
创建索引所选的列了,提示下:不能将大型对象 (LOB) 数据类型 ntext、text、varchar(max)、 nvarchar(max)、varbinary(max)、xml 或 image 的列指定为索引的键列。 另外,即使 CREATE INDEX 语句中并未引用 ntext、text 或 image 列。如果想用这些类型的列可以存放于INCLUDE里面。
- INCLUDE:
索引包含列,这个关键字非常有用,尤其在应对T-SQL的随机IO问题上,具体内容可参照我前面的一系列的文章介绍。
还有前面提到的那些大型对象(LOB)数据类型,也可以包含进去,不过这里有一点需要提示下,如果包含了大型对象,则创建索引不支持在线(ONLINE)操作,这就意味着必须选择非业务器进行操作。
- PAD_INDEX = { ON | OFF }|FILLFACTOR =fillfactor
这个两个选项是为了设置填充因子使用的,也是我们在创建索引的时候最常用的。
关于填充因子的作用简单点讲就是为了减少分页而在索引空间中提前先预留空间。我们知道对于聚集索引在叶级别就包含了数据,所以用户在这里可以指定每个叶子保留的空间的大小,通过预留空间,就可以避免用户新的数据填充而产生分页现象,产生索引碎片影响性能。
当然,关于填充因子的内容支撑,是需要一部分基础知识的,有兴趣的可以点击此参照联机丛书的官方介绍。
索引默认的的选项是OFF,也就是说基本不会预留太多空间。
关于这里填充因子设置的数值大小问题,其实没有一个固定的值,纯粹是一个经验值,来自于系统的场景和长期运行的总结。当然,如果非要给出的话,可以参照如下进行设置:
1.当读写比例大于100:1时,不要设置填充因子,100%填充
2.当写的次数大于读的次数时,设置50%-70%填充
3.当读写比例位于两者之间时80%-90%填充
但是,这个值并不是被SQL Server所维护的,也就是说在这部分预留空间填满之后,后者改数据页删除部分数据之后,还是会产生索引碎片,所以在系统运行过一段周期之后,我们需要手动的去重新整理索引,来维护好索引的秩序,维护方式也就是:重新创建,重新组织等。文章后面的会介绍。
- SORT_IN_TEMPDB = { ON | OFF }
这个就是指定当前索引排序是否要借助TempDB库,默认值为OFF。如果想快速的生成索引请将此选项指定为ON,当然弊端就是会扩大TempDB的大小,如果原表数据量特别多的话,这可能会是一个很大的空间值。
- STATISTICS_NORECOMPUTE = { ON | OFF}
这个指定是否同时更新统计信息。默认是开启的。我知道统计信息的重要性,所以在创建的时候不要更改此值。
- DROP_EXISTING = { ON | OFF }
删除或重建的时候是否重新生成已经命名先前存在的聚集或非聚集索引。默认是OFF。
这个选项非常的有用。删除或者重建索引的时候整个流程是作为一个事务来处理的。所以,通常情况下,如果打算重建一个聚集索引的时候,需要先删除聚集索引,而后再新建立一个,但是这个流程中,在删除的时候SQL Server必须重建每一个非聚集索引将每一个非聚集索引的叶子节点有聚集索引键改成RID,然后新建过程,在重复的将所有的每一个非聚集索引的叶子节点由RID键更改成新的聚集索引键值。
这就是需要重建非聚集索引两次,如果表数据量特别大的话,这个时间消耗就会很长很长…而且是阻塞的….
但是如果指定DROP_EXISTING选项为ON的话,就可以在创建或者删除的时候只需要一次更改所有非聚集索引就可以。当然此方式也可以通过ALTER INDEX做到,后面分析。
- ONLINE = { ON | OFF }
是否在线提供索引创建,此方式也是数据库的在05版本以后新添加的一大亮点,提供了在线状态下索引的创建,但是仅限于Enterprise版本。
如果在生产系统中,业务并发时期可以采用这个选项进行索引的创建及维护,但相对离线创建的时间周期要明显长很多,但是不会造成业务停机。
如果深入研究此方式的底层原理,其实就是数据的快照隔离机制,简单点将就是在创建索引的时候,将相应的数据行提供了版本控制,避免了和正常业务系统的锁争用从而避免了阻塞,属于乐观锁机制原理。
- MAXDOP = max_degree_of_parallelism
设置并行计划的数量值。这个选项也很有用,如果是非业务高发期,可以适当调高此值来并行进行索引的创建,加快索引的创建速度。
当然,也受限于物理的CPU核数。还有就是此功能也只有Enterprise版提供。
- ALLOW_ROW_LOCKS = { ON | OFF }|ALLOW_PAGE_LOCKS = { ON | OFF }
此方式指定是否行锁或者页锁,当然,只所以索引的创建和修改大部分情况下需要离线操作,就是因为在索引创建的时候加锁了。为了加快索引的生成就必须添加相应的锁。
如果 ALLOW_ROW_LOCKS = ON 且 ALLOW_PAGE_LOCK = ON,则访问索引时允许行级、页级和表级锁。数据库引擎将选择相应的锁,并且可以将锁从行锁或页锁升级到表锁。
如果 ALLOW_ROW_LOCKS = OFF 且 ALLOW_PAGE_LOCK = OFF,则访问索引时仅允许使用表级锁。
一个有用的索引的创建需要耐心的创建出来,切勿草率的鲁莽进行,如果操作不当有可能还会产生更多意外的情况。所以要充分把握好数据的特性,合理的创建好每一个有用的索引。
二、索引管理
经过上面一步的索引的创建,其实在日常的大部分时间就需要维护好索引。关于索引的维护基本就集中在以下几个方面
a、索引的重建
当我们发现索引索引覆盖范围不够或者存在大量索引锁片,影响性能的时候,我们就需要对索引进行重建。
索引范围的问题其实大部分来源于对于T-SQL语句性能的把握,也就是我们前面几篇文章中分析的需要调优的内容项。
而关于索引碎片的形成,也是源于数据库长时间的运行,大量的增删该查造成了B-Tree结构的不准确,确切的说是不能正确的提供平衡查询的性能,或者大量的数据分页造成索引碎片,进而增大了IO,影响了性能。
关于索引碎片的查看,可以通过以下DMV语句进行
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %] INTO #TempFragmentation FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempFragmentation SELECT TOP 20 DB_NAME() AS DatbaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %] FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE s.database_id = DB_ID() AND i.name IS NOT NULL AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 ORDER BY [Fragmentation %] DESC' SELECT top 20 * FROM #TempFragmentation ORDER BY [Fragmentation %] DESC DROP TABLE #TempFragmentation

看到了,这部分索引的碎片到大了99%…这就需要我们重建进行维护了,否则将严重拖垮数据的性能。
维护的方式也就主要集中在以下几种:
1、重建索引
这种方式简单高效也就是我们上面分析的CREATE INDEX 命令后面加上DROP_EXISTING方式。当然可以联机操作,操作方式参考文章前面
2、修改索引
这种方式是05版本以后才提供的,简单点将就是ALTER INDEX命令进行。其实底层的运行方式同索引重建,只不过这种方式更改的选项多一些。
3、索引重组
这种方式就是重新填充索引里面的数据,对于解决索引碎片的方式不如前面两种来的直接。不过也是一种推荐的方式,因为此方式在运行的时候,也是随时停止。
不像前面两种方式为原子性操作,并且业务阻塞。
b、索引的禁用
关于索引的禁用,这个功能也是SQL Server2005版本以后才出现的新功能,这个功能一般应用的不多。
因为大部分情况下将索引禁用了,还倒不如直接将索引删除掉来的直接。
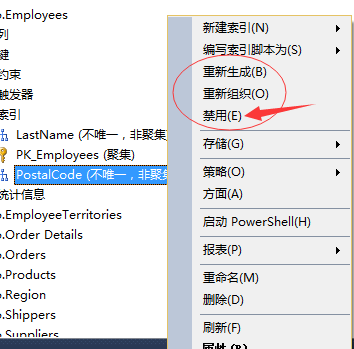
但是,记住了既然SQL Server设计了它就是有它的用武之地的。
很多情况下,数据库在运行很长一段时间之后,会发生坏页的情况。而如果通过命令查找,发现损坏也处于索引项上,那么你所做的操作就是禁用这个索引(记住只能是禁用)
然后重新建立一个新索引就可以了。
在这种情况下我们可选的最快处理方式就是禁用该索引,因为一旦发生坏页的情况,该索引项是不允许删除的。
很多朋友就好奇了,索引来了个禁用,那我什么时候启用呢?…….
嘿嘿…一旦问出了此问题,就说明了你对数据库的理解还很浅…基本上还算没有入门了……一旦索引禁用就意味着这个所以不再维护更新了….不再维护更新了那它里面的数据就是过时的或者说不准确的…那还启用它干嘛…与其启用还不如重新维护一个呢…
关于数据库坏页的情况,可以参照我前面写的一篇文章,点击此。
c、索引的删除
关于索引的删除,就不需要太多的介绍了,原因很简单,索引的存在会影响数据插入数据的速度,并且在查询的时候需要维护等多的锁,进而影响并发。
所以,一旦索引存在着一点优化的作用没有,我们就要及时的删除掉,因为百害而无一利嘛。
查看未使用的索引DMV脚本如下:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(O.Schema_ID) AS SchemaName , OBJECT_NAME(I.object_id) AS TableName , I.name AS IndexName INTO #TempNeverUsedIndexes FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempNeverUsedIndexes SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(O.Schema_ID) AS SchemaName , OBJECT_NAME(I.object_id) AS TableName , I.NAME AS IndexName FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id LEFT OUTER JOIN sys.dm_db_index_usage_stats S ON S.object_id = I.object_id AND I.index_id = S.index_id AND DATABASE_ID = DB_ID() WHERE OBJECTPROPERTY(O.object_id,''IsMsShipped'') = 0 AND I.name IS NOT NULL AND S.object_id IS NULL' SELECT * FROM #TempNeverUsedIndexes ORDER BY DatbaseName, SchemaName, TableName, IndexName DROP TABLE #TempNeverUsedIndexes
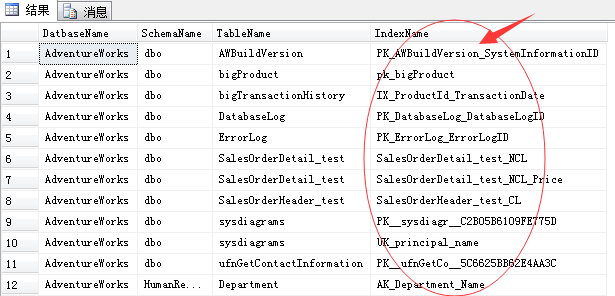
当然,这些记录都是自动SQL Server启动以来未曾使用的索引,所以在生产系统中,一定要确保已经运行了一段周期了。
索引脚本的删除,很简单和表删除类似,直接drop掉就可以了。
当然,最后再赠送一个DMV,查看那些经常被大量更新,但是却基本不适用的索引项
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatabaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , s.user_updates , s.system_seeks + s.system_scans + s.system_lookups AS [System usage] INTO #TempUnusedIndexes FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempUnusedIndexes SELECT TOP 20 DB_NAME() AS DatabaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , s.user_updates , s.system_seeks + s.system_scans + s.system_lookups AS [System usage] FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 AND s.user_seeks = 0 AND s.user_scans = 0 AND s.user_lookups = 0 AND i.name IS NOT NULL ORDER BY s.user_updates DESC' SELECT TOP 20 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC DROP TABLE #TempUnusedIndexes