前言
上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布。不清楚的童鞋可以点击参考。
作为调优系列的文章,数据库的索引肯定是不能少的了,所以本篇我们就开始分析这块内容,关于索引的基础知识就不打算深入分析了,网上一搜一片片的,本篇更侧重的是一些实战项内容展示,希望通过本篇文章各位看官能在真正的场景中找到合适的解决方法足以。
对于索引的使用,我希望的是遇到问题找到合适的解决方法就可以,切勿乱用!!!
本篇在分析出索引的优越性的同时也将负面影响展现出来。
技术准备
数据库版本为SQL Server2012,前几篇文章用的是SQL Server2008RT,内容区别不大,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks
相信了解SQL Server的朋友,对这两个库都不会太陌生。
概念理解
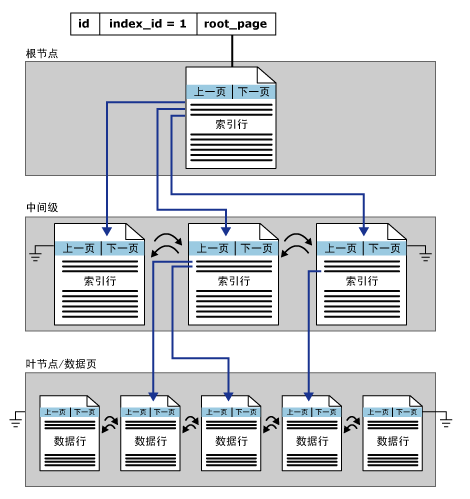
所谓的索引同SQL Server中的其它类型的数据页一样,也是固定的8KB(8192字节),存储方式同为B-Tree结构,索引B树中的每一页称为一个索引节点。B树顶端节点为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引统称为中间级。
算了,描述起来太麻烦,联机丛书上截个图直观的展示结构: