
前言
上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握。
通过本篇可以了解我们平常所写的T-SQL语句,在SQL Server数据库系统中是如何分解执行的,数据结果如何通过各个运算符组织形成的。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、数据连接
数据连接是我们在写T-SQL语句的时候最常用的,通过两个表之间关联获取想要的数据。
SQL Server默认支持三种物理连接运算符:嵌套循环连接、合并连接以及哈希连接。三种连接各有用途,各有特点,不同的场景会数据库会为我们选择最优的连接方式。
a、嵌套循环连接(nested loops join)
嵌套循环连接是最简单也是最基础的连接方式。两张表通过关键字进行关联,然后通过双层循环依次进行两张表的行进行关联,然后通过关键字进行筛选。
可以参照下图进行理解分析
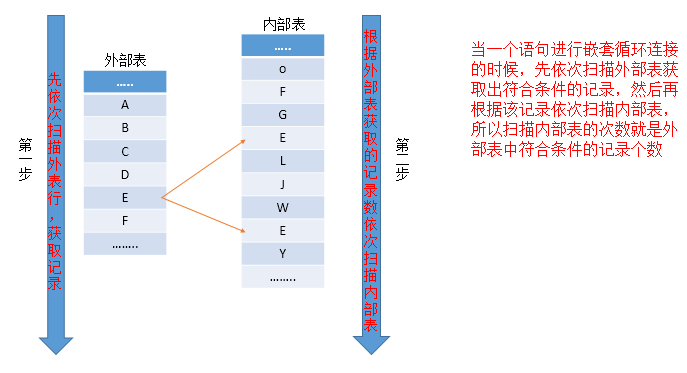
其实嵌套扫描是很简单的获取数据的方式,简单点就是两层循环过滤出结果值。
我们可以通过如下代码加深理解
for each row R1 in the outer table
for each row R2 int the inner table
if R1 join with R2
return (R1,R2)
举个列子
SELECT o.OrderID FROM Customers C JOIN Orders O ON C.CustomerID=O.CustomerID WHERE C.City=N'London'

以上这个图标就是嵌套循环连接的图标了。而且解释的很明确。

这种方法的消耗就是外表和内表的乘积,其实就是我们所称呼的笛卡尔积。所以消耗的大小是随着两张表的数据量增大而增加的,尤其是内部表,因为它是多次重复扫描的,所以我们在实践中的采取的措施就是减少每个外表或者内表的行数来减少消耗。
对于这种算法还有一种提高性能的方式,因为两张表是通过关键字进行关联的,所以在查询的时候对于底层的数据获取速度直接关乎着此算法的性能,这里优化的方式尽量使用两个表关键字为索引查询,提高查询速度。
还有一点就是在嵌套循环连接中,在两张表关联的时候,对外表都是有筛选条件的,比如上面例子中【WHERE C.City=N’London’】就是对外表(Customers)的筛选,并且这里的City列在该表中存在索引,所以该语句的两个子查询都为索引查 找(Index Seek)。
但是,有些情况我们的查询条件不是索引所覆盖的,这时候,在嵌套循环连接下的子运算符就变成了索引扫描(Index scan)或者RID查找。
举个例子
SELECT E1.EmployeeID,COUNT(*) FROM Employees E1 JOIN Employees E2 ON E1.HireDate<E2.HireDate GROUP BY E1.EmployeeID
以上代码是从职工表中获取出每位职工入职前的人员数。我们看一下该查询的执行计划
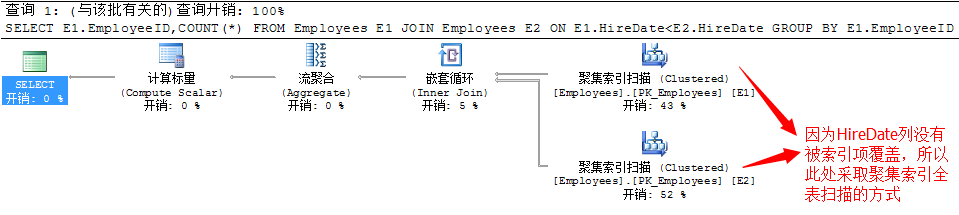
这里很显然两个表的关联通过的是HireDate列进行,而此列又不为索引项所覆盖,所以两张表的获取只能通过全表的聚集索引扫描进行,如果这两张表数据量特别大的话,无疑又是一个非常耗性能的查询。

通过文本可以看出,该T-SQL的查询结果的获取是通过在嵌套循环运算符中,对两个表经过全表扫描之后形成的笛卡儿积进行过滤筛选的。这种方式其实 不是一个最优的方式,因为我们获取的结果其实是可以先通过两个表过滤之后,再通过嵌套循环运算符获取结果,这样的话性能会好很多。
我们尝试改一下这个语句
SELECT E1.EmployeeID,ECNT.CNT FROM Employees E1 CROSS APPLY ( SELECT COUNT(*) CNT FROM Employees E2 WHERE E1.HireDate<E2.HireDate )ECNT
通过上述代码查询的结果项,和上面的是一样的,只是我们根据外部表的结果对内部表进行了过滤,这样执行的时候就不需要获取全部数据项了。
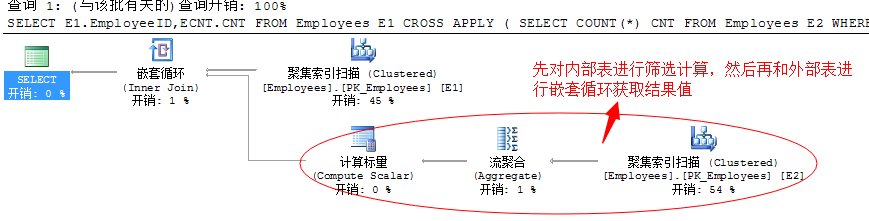
我们查看下文本执行计划

我们比较一下,前后两条语句的执行消耗,对比一下执行效率
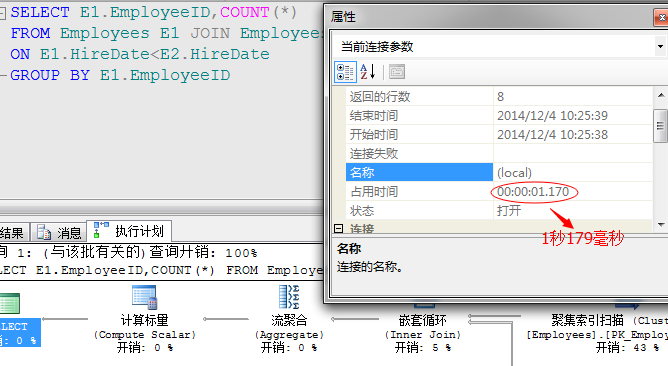
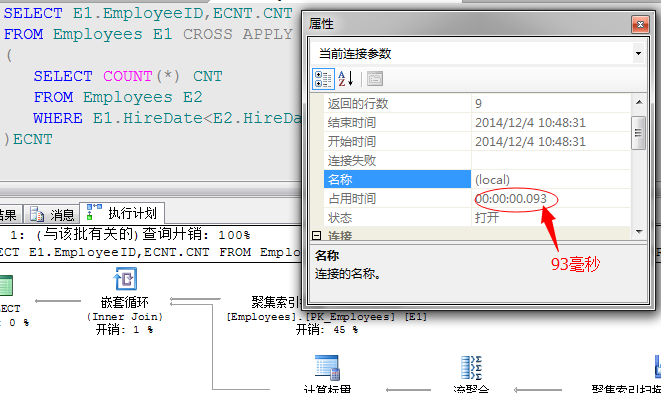
执行时间从1秒179毫秒减少至93毫秒。效果明显。
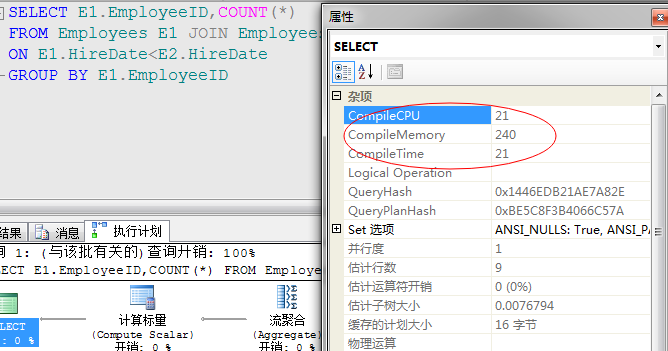
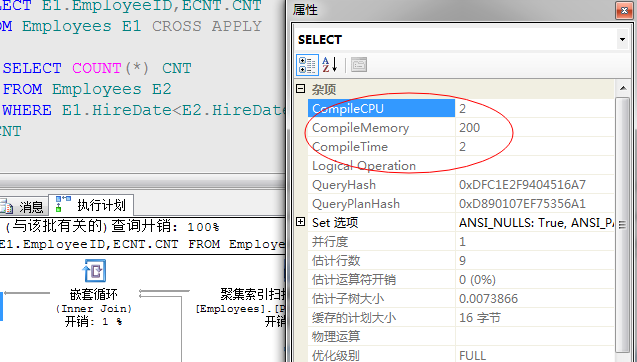
对比CPU消耗、内存、编译时间等总体消耗都有所降低,参考上图。
所以对嵌套循环连接连接的优化方式就是集中在这几点:对两张表数据量的减少、连接关键字上建立索引、谓词查询条件上覆盖索引最好能减少符合谓词条件的记录数。
b、合并连接(merge join)
上面提到的嵌套循环连接方式存在着诸多的问题,尤其不适合两张表都是大表的情况下,因为它会产生N多次的全表扫描,很显然这种方式会严重的消耗资源。
鉴于上述原因,在数据库里又提供了另外一种连接方式:合并连接。记住这里没有说SQL Server所提供的,是因为此连接算法是市面所有的RDBMS所共同使用的一种连接算法。
合并连接是依次读取两张表的一行进行对比。如果两个行是相同的,则输出一个连接后的行并继续下一行的读取。如果行是不相同的,则舍弃两个输入中较少 的那个并继续读取,一直到两个表中某一个表的行扫描结束,则执行完毕,所以该算法执行只会产生每张表一次扫描,并且不需要整张表扫描完就可以停止。
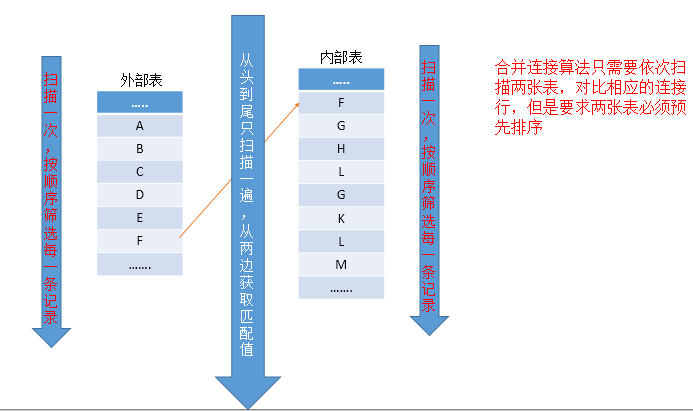
该算法要求按照两张表进行依次扫描对比,但是有两个前提条件:1、必须预先将两张表的对应列进行排序;2、对两张表进行合并连接的条件必须存在等值连接。
我们可以通过以下代码进行理解
get first row R1 from input1
get first row R2 from input2
while not at the end of either input
begin
if R1 joins with R2
begin
output(R1,R2)
get next row R2 from input2
end
else if R1<R2
get next row R1 from input1
else
get next row R2 from input2
end
合并连接运算符总的消耗是和输入表中的行数成正比的,而且对表最多读取一次,这个和嵌套循环连接不一样。因此,合并连接对于大表的连接操作是一个比较好的选择项。
对于合并连接可以从如下几点提高性能:
- 两张表间的连接值内容列类型,如果两张表中的关联列都为唯一列,也就说都不存在重复值,这种关联性能是最好的,或者有一张表存在唯一列也可以,这 种方式关联为一对多关联方式,这种方式也是我们最常用的,比我们经常使用的主从表关联查询;如果两张表中的关联列存在重复值,这样在两表进行关联的时候还 需要借助第三张表来暂存重复的值,这第三张表叫做”worktable “是存放在Tempdb或者内存中,而这样性能就会有所影响。所以鉴于此,我们常做的优化方式有:关联连尽量采用聚集索引(唯一性)
- 我们知道采用该种算法的前提是,两张表都经过排序,所以我们在应用的时候,最好优先使用排序后的表关联。如果没有排序,也要选择的关联项为索引覆盖项,因为大表的排序是一个很耗资源的过程,我们选择索引覆盖列进行排序性能要远远好于普通列的排序。
我们来举个例子
SELECT O.CustomerID,C.CustomerID,C.ContactName FROM Orders O JOIN Customers C ON O.CustomerID=C.CustomerID
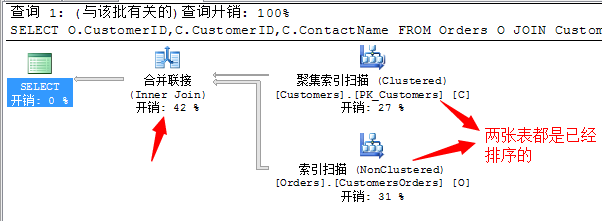
我们知道这段T-SQL语句中关联项用的是CustomerID,而此列为主键聚集索引,都是唯一的并且经过排序的,所以这里面没有显示的排序操作。
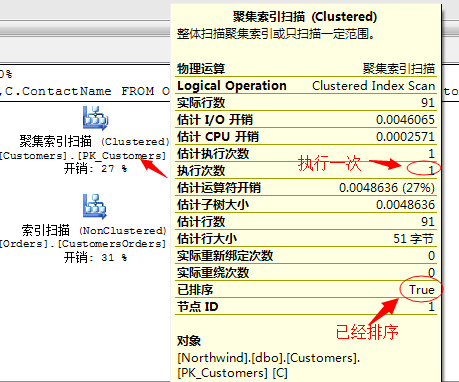
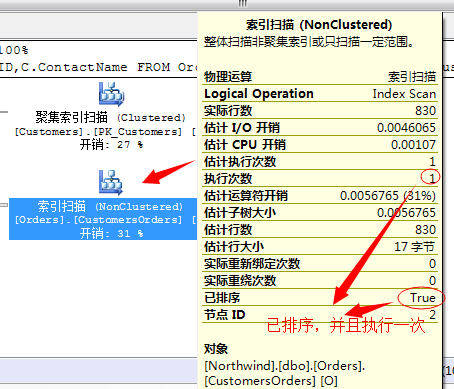
而且凡是采用合并连接的所有输出结果项,都是已经经过排序的。
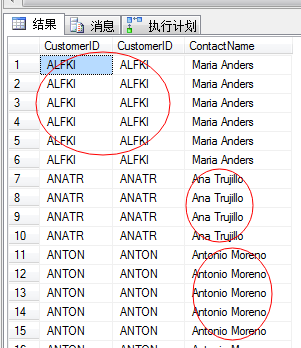
我们找一个稍复杂的情况,没有提前排序的利用合并查询的T-SQL
SELECT O.OrderID,C.CustomerID,C.ContactName FROM Orders O JOIN Customers C ON O.CustomerID=C.CustomerID AND O.ShipCity<>C.City ORDER BY C.CustomerID
上述代码返回那些客户的发货订单不在客户本地的。
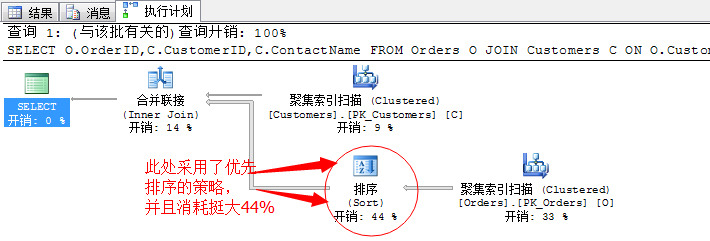
上面的查询计划可以看出,排序的消耗总是巨大的,其实我们上面的语句按照逻辑应该是在合并连接获取数据后,才采用显示的按照CustomerID进行排序。
但是因为合并连接运算符之前本身就需要排序,所以此处SQL Server采取了优先排序的策略,把排序操作提前到了合并连接之前进行,并且在合并连接之后,就不需要在做额外的排序了。
这其实这里我们要求对查询结果排序,正好也利用了合并连接的特点。
c、哈希连接(hash join)
我们分析了上面的两种连接算法,两种算法各有特点,也各有自己的应用场景:嵌套循环连接适合于相对小的数据集连接,合并连接则应对与中型的数据集,但是又有它自己的缺点,比如要求必须有等值连接,并且需要预先排序等。
那对于大型的数据集合的连接数据库是怎么应对的呢?那就是哈希连接算法的应用场景了。
哈希连接对于大型数据集合的并行操作上都比其它方式要好很多,尤其适用于OLAP数据仓库的应用场景中。
哈希连接很多地方和合并连接类似,比如都需要至少一个等值连接,同样支持所有的外连接操作。但不同于合并连接的是,哈希连接不需要预先对输入数据集合排序,我们知道对于大表的排序操作是一个很大的消耗,所以去除排序操作,哈希操作性能无疑会提升很多。
哈希连接在执行的时候分为两个阶段:
- 构建阶段
在构建阶段,哈希连接从一个表中读入所有的行,将等值连接键的行机型哈希话处理,然后创建形成一个内存哈希表,而将原来列中行数据依次放入不同的哈希桶中。

- 探索阶段
在第一个阶段完成之后,开始进入第二个阶段探索阶段,该阶段哈希连接从第二个数据表中读入所有的行,同样也是在相同的等值连接键上进行哈希。哈希过程桶上一阶段,然后再从哈希表中探索匹配的行。
上述的过程中,在第一个阶段的构建阶段是阻塞的,也就是说在,哈希连接必须读入和处理所有的构建输入,之后才能返回行。而且这一过程是需要一块内存存储提供支持,并且利用的是哈希函数,所以相应的也会消耗CPU等。
并且上述流程过程中一般采用的是并发处理,充分利用资源,当然系统会对哈希的数量有所限制,如果数据量超大,也会发生内存溢出等问题,而对于这些问题的解决,SQL Server有它自身的处理方式。
我们可通过以下代码进行理解
--构建阶段
for each row R1 in the build table
begin
calculate hash value on R1 join key(s)
insert R1 into the appropriate hash bucket
end
--探索阶段
for each row R2 in the probe table
begin
calculate hash value on R2 join key(s)
for each row R1 in the corresponding hash bucket
if R1 joins with R2
output(R1,R2)
end
在哈希连接执行之前,SQL Server会估算需要多少内存来构建哈希表。基本估算的方式就是通过表的统计信息来估算,所以有时候统计信息不准确,会直接影响其运算性能。
SQL Server默认会尽力预留足够的内存来保证哈希连接成功的构建,但是有时候内存不足的情况下,就必须采取将一小部分的哈希表分配到硬盘中,这里就存入到了tempdb库中,而这一过程会反复多次循环执行。
举个列子来看看
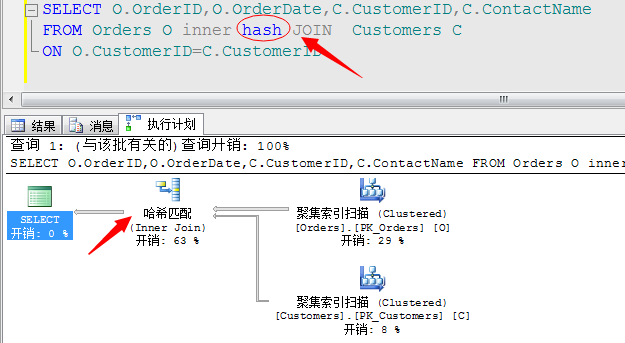
SELECT O.OrderID,O.OrderDate,C.CustomerID,C.ContactName FROM Orders O JOIN Customers C ON O.CustomerID=C.CustomerID
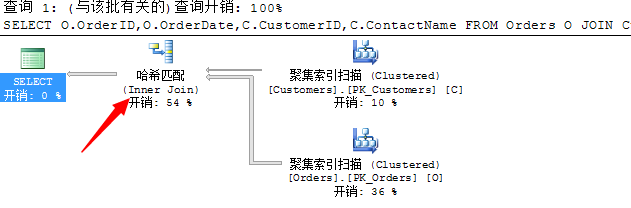
我们来分析上面的执行语句,上面的执行结果通过CustomerID列进行关联,理论将最合适的应该是采用合并连接操作,但是合并连接需要排序,但是我们在语句中没有指定Order by 选项,所以经过评估,此语句采用了哈希连接的方式进行了连接。
我们给它加上一个显示的排序,它就选用合并连接作为最优的连接方式
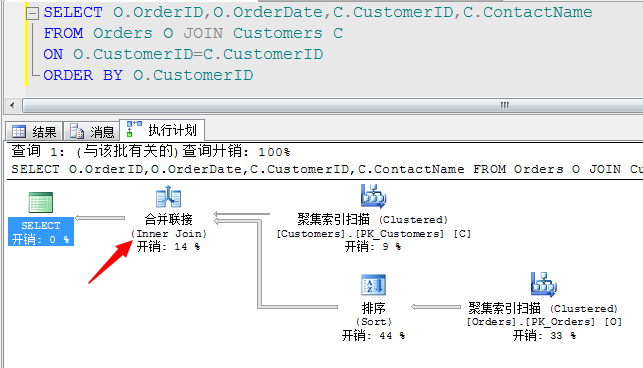
我们来总结一下这个算法的特点
- 和合并连接一样算法复杂度基本就是分别遍历两边的数据集各一遍
- 它不需要对数据集事先排序,也不要求上面有什么索引,通过的是哈希算法进行处理
- 基本采取并行的执行计划的方式
但是,该算法也有它自身的缺点,因为其利用的是哈希函数,所以运行时对CPU消耗高,同样对内存也比较大,但是它可以采用并行处理的方式,所以该算法用于超大数据表的连接查询上显示出自己独有的优势。
关于哈希算法在哈希处理过程的时候对内存的占用和分配方式,是有它自己独有哈希方法,比如:左深度树、右深度树、浓密哈希连接树等,这里不做详细介绍了,只需要知道其使用方式就可以了。
Hash Join并不是一种最优的连接算法,只是它对输入不优化,因为输入数据集特别大,并且对连接符上有没有索引也没要求。其实这也是一种不得已的选择,但是该 算法又有它适应的场景,尤其在OLAP的数据仓库中,在一个系统资源相对充足的环境下,该算法就得到了它发挥的场景。
当然前面所介绍的两种算法也并不是一无是处,在业务的OLTP系统库中,这两种轻量级的连接算法,以其自身的优越性也获得了认可。
所以这三种算法,没有谁好谁坏,只有合适的场景应用合适的连接算法,这样才能发挥它自身的长处,而恰巧这些就是我们要掌握的技能。
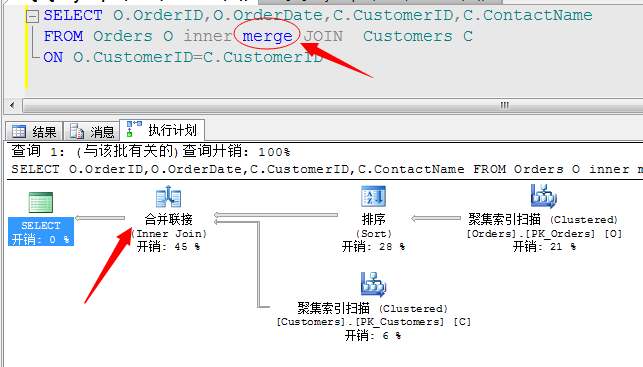
这三种连接算法我们也可以显示的指定,但是一般不建议这么做,因为默认SQL Server会为我们评估最优的连接方式进行操作,当然有时候它评估不对的时候就需要我们自己指定了,方法如下:

二、聚合操作
聚合也是我们在写T-SQL语句的时候经常遇到的,我们来分析一下一些常用的聚合操作运算符的特性和可优化项。
a、标量聚合
标量聚合是一种常用的数据聚合方式,比如我们写的语句中利用的以下聚合函数:MAX()、MIN()、AVG()、COUNT()、SUM()
以上的这些数据结果项的输出基本都是通过流聚合的方式产生,并且这个运算符也被称为:标量聚合
先来看一个列子
SELECT COUNT(*) FROM Orders
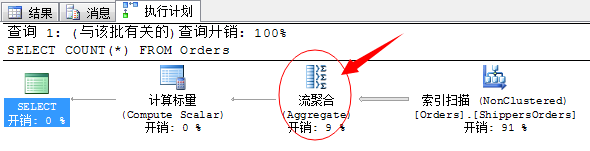
上面的图表就是流聚合的运算符了。
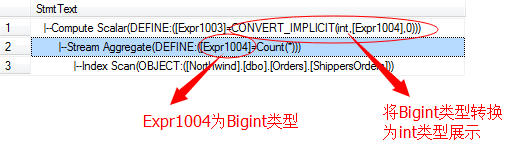
上图还有一个计算标量的运算符,这是因为在流聚合产生的结果项数据类型为Bigint类型,而默认输出为int类型,所以增加了一个类型转换的运算符。
我们来看一个不需要转换的
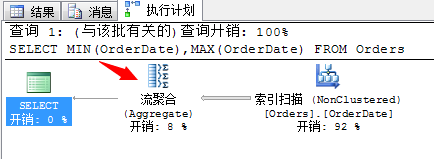
SELECT MIN(OrderDate),MAX(OrderDate) FROM Orders
看一下求平均数的运算符
SELECT AVG(Freight) FROM Orders

求平均数的时候,在SQL Server执行的时候也给我们添加了一个case when分类,防止分母为0的情况发生。
我们来看DISTINCT下的情况下,执行计划
SELECT COUNT(DISTINCT ShipCity) FROM Orders SELECT COUNT(DISTINCT OrderID) FROM Orders


上面相同的语句,但是产生了不同的执行计划,只是因为发生在不同列的数量汇总上,因为OrderID不存在重复列,所以SQL Server不需要排序直接流聚合就可以产生汇总值,而ShipCity不同它会有重复的值,所以只能经过排序后再流聚合依次获取汇总值。
其实,流聚合这种算法最常用的方式是分组(GROUP BY)计算,上面的标量计算也是利用这个特性,只不过把整体形成了一个大组进行聚合。
我么通过如下代码理解
clear the current aggredate results
clear the current group by columns
for each input row
begin
if the input row does not match the current group by columns
begin
output the current aggreagate results(if any)
clear the current aggreagate results
set the current group by columns to the input row
end
update the aggregate results with the input row
end
流聚合运算符其实过程很简单,维护一个聚合组和聚合值,依次扫描表中的数据,如果能匹配聚合组则忽略,如果不匹配,则加入到聚合组中并且更新聚合值结果项。
举个例子
SELECT ShipAddress,ShipCity,COUNT(*) FROM Orders GROUP BY ShipAddress,ShipCity
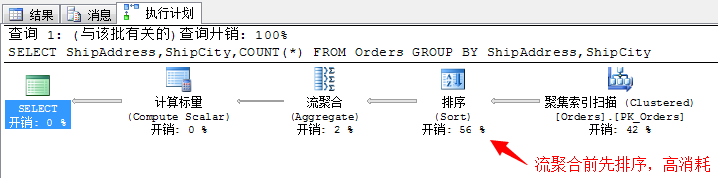
这里使用了流聚合,并且之前先对两列进行排序,排序的消耗总是很大。
如下代码就不会产生排序
SELECT CustomerID,COUNT(*) FROM Orders GROUP BY CustomerID

所以这里我们已经总结出对于流聚合的一种优化方式:尽量避免排序产生,而要避免排序就需要将分组(Group by)字段在索引覆盖范围内。
b、哈希聚合
上述的流聚合的方式需要提前排序,我们知道排序是一个非常大的消耗过程,所以不适合大表的分组聚合操作,为了解决这个问题,又引入了另外一种聚合运算:哈希聚合
所谓的哈希聚合内部的方法和本篇前面提到的哈希连接机制一样。
哈希聚合不需要排序和过大的内存消耗,并且很容易并行执行计划,利用多CPU同步进行,但是有一个缺点就是:这一过程是阻塞的,也就说哈希聚合不会产生任何结果直到完整的输入。
所以在大数据表中采用哈希聚合是一个很好的应用场景。
通过如下代码加深理解
for each input row
begin
calculate hash value on group by columns
check for a matching row in the hash table
if maching row not found
insert a new row into the hash table
else
update the matching row with the input row
end
--最后输出结果
ouput all rows in the hash table
简单点将就是在进行运算匹配前,先将分组列进行哈希处理,分配至不同的哈希桶中,然后再依次匹配,最后才输出结果。
举个例子
SELECT ShipCountry,COUNT(*) FROM Orders GROUP BY ShipCountry

这个语句很有意思,我们利用了ShipCountry进行了分组,我们知道该列没有被索引覆盖,按照道理,其实选择流聚合应该也是不错的方式,跟上面我们列举的列子一样,先对这个字段进行排序,然后利用流聚合形成结果项输出。
但是,为什么这个语句SQL Server为我们选择了哈希匹配作为了最优的算法呢!!!
我么来比较两个分组字段:ShipCountry和前面的ShipAddress
前面是国家,后面是地址,国家是很多重复的,并且只有少数的唯一值。而地址就不一样了,离散型的分布,我们知道排序是很耗资源的一件事情,但是利用哈希匹配只需要将不同的列值进行提取就可以,所以相比性能而言,无疑哈希匹配算法在这里是略胜一筹的算法。
而上面关于这两列内容分布类型SQL Server是怎样知道的?这就是SQL Server的强大的统计信息在支撑了。
在SQL Server中并不是固定的语句就会形成特定的计划,并且生成的特定计划也不是总是最优的,这和数据库现有数据表中的内容分布、数据量、数据类型等诸多因素有关,而记录这些详细信息的就是统计信息。
所有的最优计划的选择都是基于现有统计信息来评估,如果我们的统计信息未及时更新,那么所评估出来最优的执行计划将不是最好的,有时候反而是最烂的。
结语
此篇文章先到此吧,本篇主要介绍了关于T-SQL语句调优从执行计划下手,并介绍了三个常见的连接运算符和聚合操作符,下一篇将着重介绍我们其它最 常用的一些运算符和调优技巧,包括:CURD等运算符、联合运算符、索引运算、并行运算等吧,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。