技术准备
数据库版本为SQL Server2012,前几篇文章用的是SQL Server2008RT,内容区别不大,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
一、创建索引
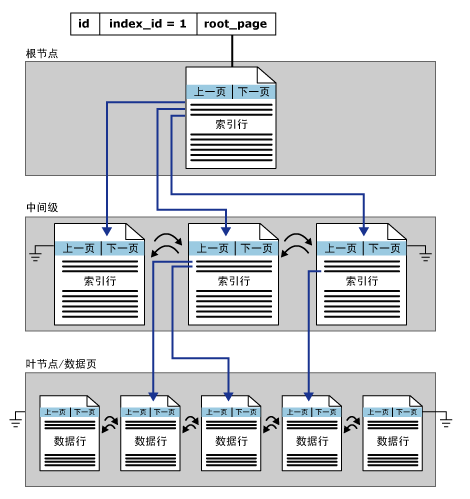
当我们要开始对表进行索引的创建的时候,首先明确的是,一张表内只能创建一个聚集索引,最多可以创建最多249个非聚集索引(SQL Server2005),在SQL Server2008以后聚集索引数提升至999个,上一篇文章我们知道对于聚集索引项一般要创建上,而非聚集索引项要根据日常的T-SQL语句进行选择。
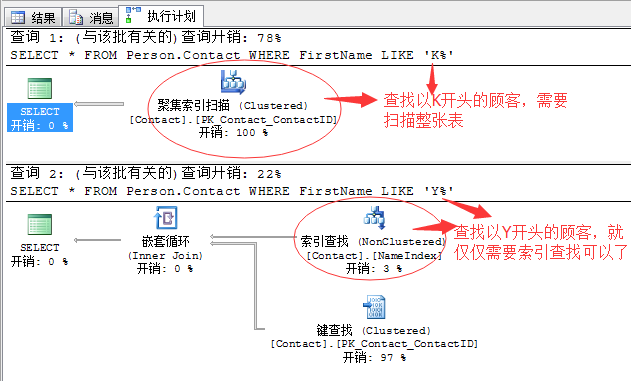
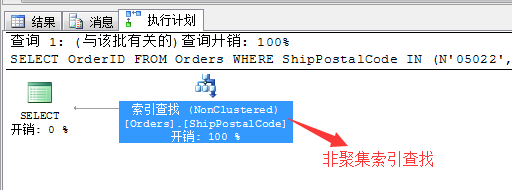
关于索引的选择是一个很考验调优能力的事情,大部分的情况下优质的索引新建全靠经验而论,有兴趣的可以点击查阅我前面的一系列关于分析查询计划的文章,掌握住里面的精髓才能有的放矢。
当然,小白级别的也可以参照如下方法尝试进行创建:
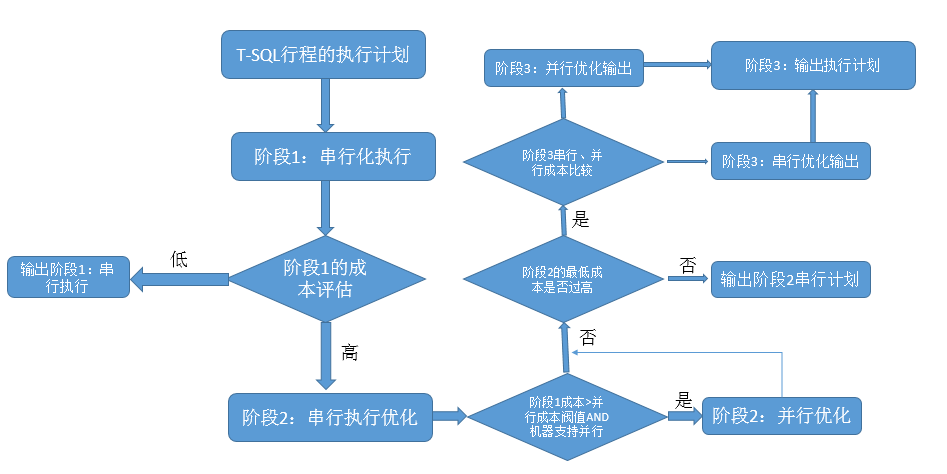
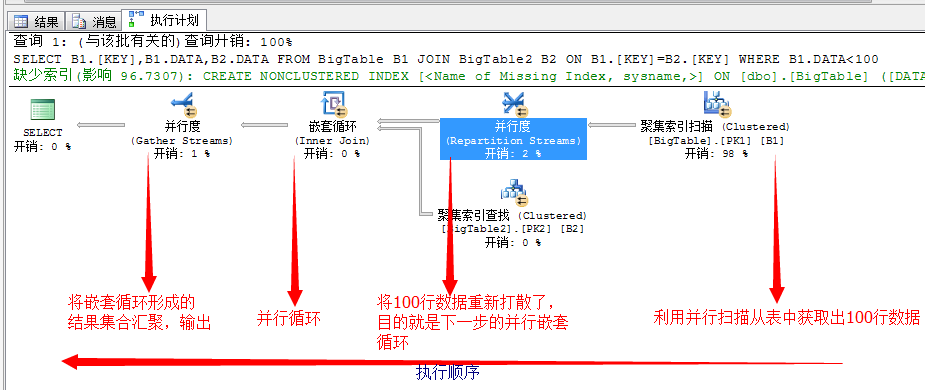
由于SQL Server有着自己的一套调优技巧,所以在我们每次运行的T-SQL语句应该怎样优化,SQL Server是了如指掌的,所以它会将缺失的索引项进行记录,用于提示使用者,尝试去建立这些索引。
主要记录在以下几个DMV中
sys.dm_db_missing_index_details sys.dm_db_missing_index_groups sys.dm_db_missing_index_group_stats sys.dm_db_missing_index_columns(index_handle) sys.dm_db_missing_index_details