
前言
上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符、联合运算符的优化技巧。
本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自己的查询计划,来适应硬件资源的扩展,充分利用硬件资源,最大限度的提高性能。
闲言少叙,直接进入本篇的正题。
技术准备
同前几篇一样,基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、并行运算符
在我们日常所写的T-SQL语句,并不是所有的最优执行计划都是一样的,其最优的执行计划的形成需要多方面的评估才可以,大部分根据SQL Server本身所形成的统计信息,然后对形成的多个执行计划进行评估,进而选出最优的执行方式。
在SQL Server根据库内容形成的统计信息进行评估的同时,还要参照当前运行的硬件资源,有时候它认为最优的方案可能当前硬件资源不支持,比如:内存限制、CPU限制、IO瓶颈等,所以执行计划的优劣还要依赖于底层硬件。
当SQL Server发现某个处理的数据集比较大,耗费资源比较多时,但此时硬件存在多颗CPU时,SQL Server会尝试使用并行的方法,把数据集拆分成若干个,若干个线程同时处理,来提高整体效率。
在SQL Server中可以通过如下方法,设置SQL Server可用的CPU个数
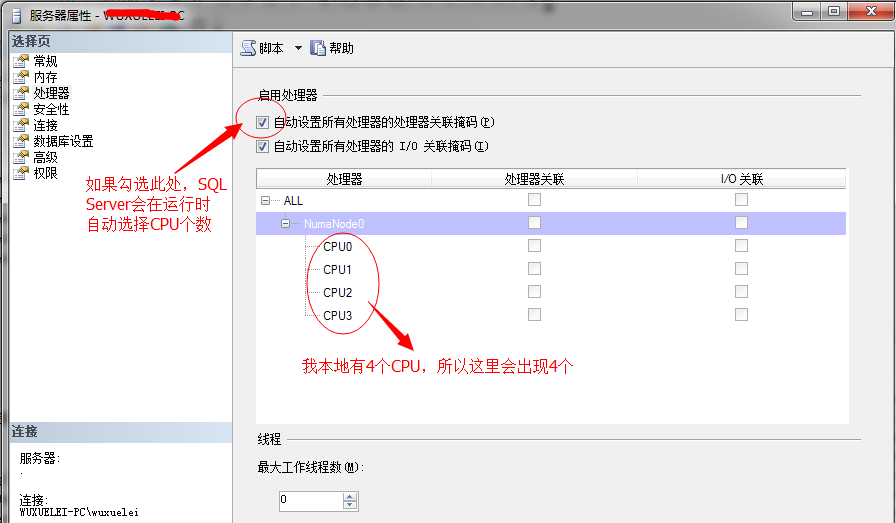
默认SQL Server会自动选择CPU个数,当然不排除某些情况下,比如高并发的生产环境中,防止SQL Server独占所有CPU,所以提供了该配置的界面。
还有一个系统参数,就是我们熟知的MAXDOP参数,也可以更改此系统参数配置,该配置也可以控制每个运算符的并行数(记住:这里是每个运算符的,而非全部的),我们来查看该参数
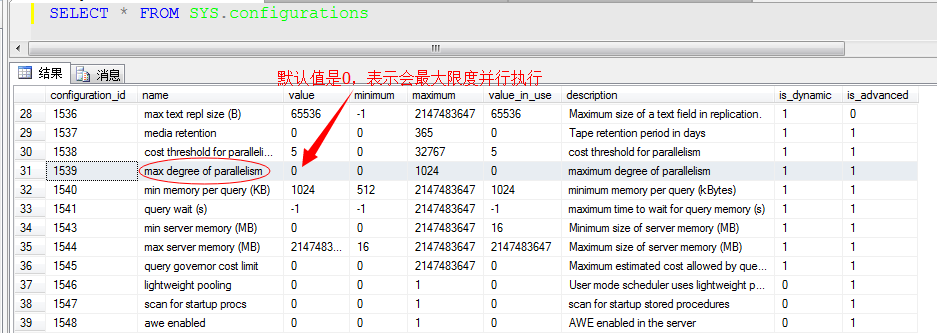
这个并行运算符的设置数,指定的是每个运算符的最大并行数,所以有时候我们利用查看系统任务数的DMV视图sys.dm_os_tasks来查 看,很可能看到大于并行度的线程数据量,也就是说线程数据可能超过并行度,原因就是两个运算符重新划分了数据,分配到不同的线程中。
这里如没特殊情况的话,建议采用默认设置最佳。
我们举一个分组的例子,来理解并行运算
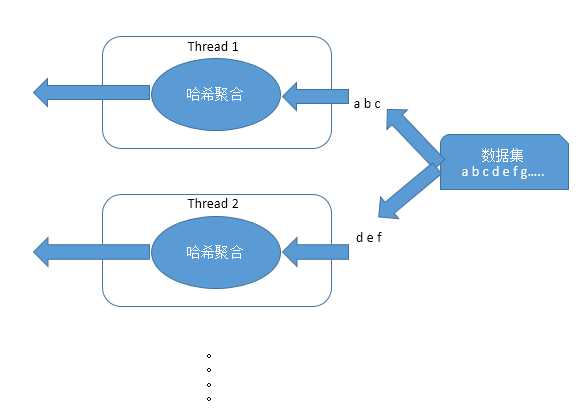
采用并行运算出了提升性能还有如下几个优点:
- 不依赖于线程的数量,在运行时自动的添加或移除线程,在保证系统正常吞吐率的前提下达到一个性能最优值
- 能够适应倾斜和负载均衡,比如一个线程运行速度比其它线程慢,这个线程要扫描或者运行的数量会自动减少,而其它跑的快的线程会相应提高任务数,所以总的执行时间就会平稳的减少,而非一个线程阻塞整体性能。
下面我们来举个例子,详细的说明一下
并行计划一般应用于数据量比较大的表,小表采用串行的效率是最高的,所以这里我们新建一个测试的大表,然后插入部分测试数据,我们插入250000行,整体表超过6500页,脚本如下
--新建表,建立主键,形成聚集索引
CREATE TABLE BigTable
(
[KEY] INT,
DATA INT,
PAD CHAR(200),
CONSTRAINT [PK1] PRIMARY KEY ([KEY])
)
GO
--批量插入测试数据250000行
SET NOCOUNT ON
DECLARE @i INT
BEGIN TRAN
SET @i=0
WHILE @i<250000
BEGIN
INSERT BigTable VALUES(@i,@i,NULL)
SET @i=@i+1
IF @i%1000=0
BEGIN
COMMIT TRAN
BEGIN TRAN
END
END
COMMIT TRAN
GO
我们来执行一个简单查询的脚本
SELECT [KEY],[DATA] FROM BigTable
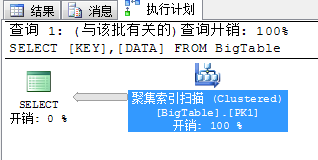
这里对于这种查询脚本,没有任何筛选条件的情况下,没必要采用并行扫描,因为采用串行扫描的方式得到数据的速度反而比并行扫描获取的快,所以这里采用了clustered scan的方式,我们来加一个筛选条件看看
SELECT [KEY],[DATA] FROM BigTable WHERE DATA<1000
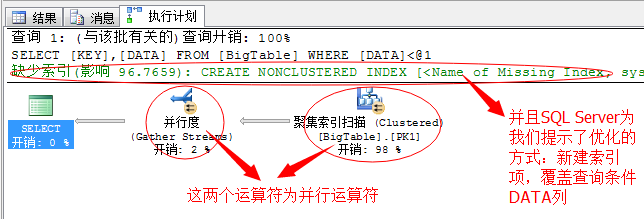
对于这个有筛选条件的T-SQL语句,这里SQL Server果断的采用的并行运算的方式,聚集索引也是并行扫描,因为我电脑为4个逻辑CPU(其实是2颗物理CPU,4线程),所以这里使用的是4线程并行扫描四次表,每个线程扫描一部分数据,然后汇总。
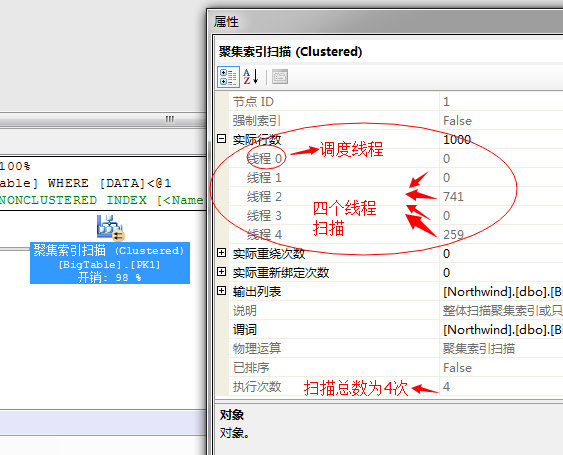
这里总共用了4个线程,其中线程0为调度线程,负责调度所有的其它线程,所以它不执行扫描,而线程1到线程4执行了这1000行的扫描!当然这里数据量比较少,有的线程分配了0个任务,但是总得扫描次数为4次,所以这4个线程是并行的扫描了这个表。
可能上面获取的结果比较简单,有的线程任务还没有给分配满,我们来找一个相对稍复杂的语句
SELECT MIN([DATA]) FROM BigTable

这个执行计划挺简单的,我们依次从右边向左分析,依次执行为:
4个并行聚集索引扫描——>4个线程并行获取出前当前线程的最小数——>执行4个最小数汇总——>执行流聚合获取出4个数中的最小值——>输出结果项。
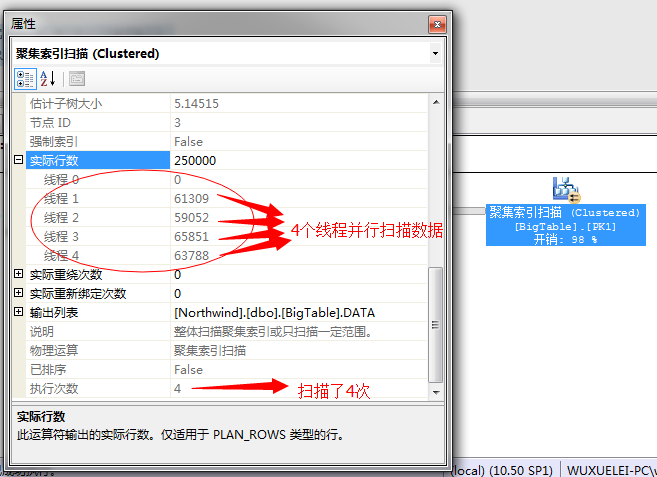
然后4个线程,每个线程一个流聚合获取当前线程的最小数

然后,将这个四个最小值经过下一个“并行度”的运算符汇聚成一个表

然后下一个就是流聚合,从这个4行数据中获取出最小值,进行输出,关于流聚合我们上一篇文章中已经介绍
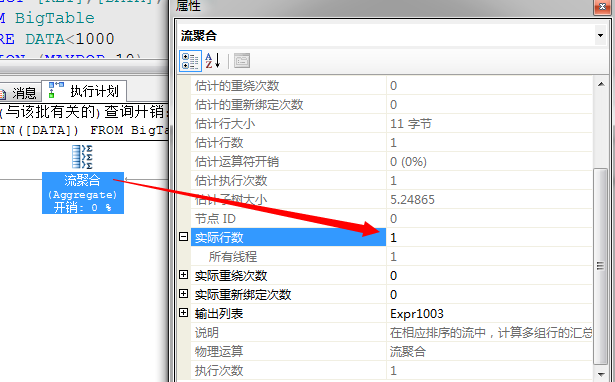
以上就一个一个标准的多线程并行运算的过程。
上面的过程中,因为我们使用的并行聚集索引扫描数据,4个线程基本上是平均分摊了任务量,也就是说每个线程扫描的数据量基本相等,下面我们将一个线程使其处于忙碌状态,看看SQL Server会不会将任务动态的平摊到其它几个不忙碌的线程上。
我们在来添加一个大数据量表,脚本如下
SELECT [KEY],[DATA],[PAD] INTO BigTable2 FROM BigTable
我们来写一个大量语句的查询,使其占用一个线程,并且我们这里强制指定只用一个线程运行
SELECT MIN(B1.[KEY]+B2.[KEY]) FROM BigTable B1 CROSS JOIN BigTable2 B2 OPTION(MAXDOP 1)
以上代码想跑出结果,就我这个电脑配置估计少说五分钟以上,并且我们还强行串行运算,速度可想而知,
我们接着执行上面的获取最小值的语句,查看执行计划
SELECT MIN([DATA]) FROM BigTable
我们在执行计划中,查看到了聚集索引扫描的线程数量

可以看到,线程1已经数量减少了近四分之的数据,并且从线程1到线程4,所扫描的数据量是依次增加的。
我们上面的语句很明确的指定了MAXDOP为1,理论上讲只可能会影响一个线程,为什么这几个线程都影响呢?其实这个原因很简单,我的电脑是物理CPU只有两核,所谓的线程数只是超线程,所以非传统意义上的真正的4核数,所以线程之间是互相影响的。
我们来看一个并行连接操作的例子,我们查看并行嵌套循环是怎样利用资源的
SELECT B1.[KEY],B1.DATA,B2.DATA FROM BigTable B1 JOIN BigTable2 B2 ON B1.[KEY]=B2.[KEY] WHERE B1.DATA<100
上面的语句中,我们在BigTable中Key列存在聚集索引,而查询条件中DATA列不存在,所以这里肯定为聚集索引扫描,对数据进行查找
来看执行计划
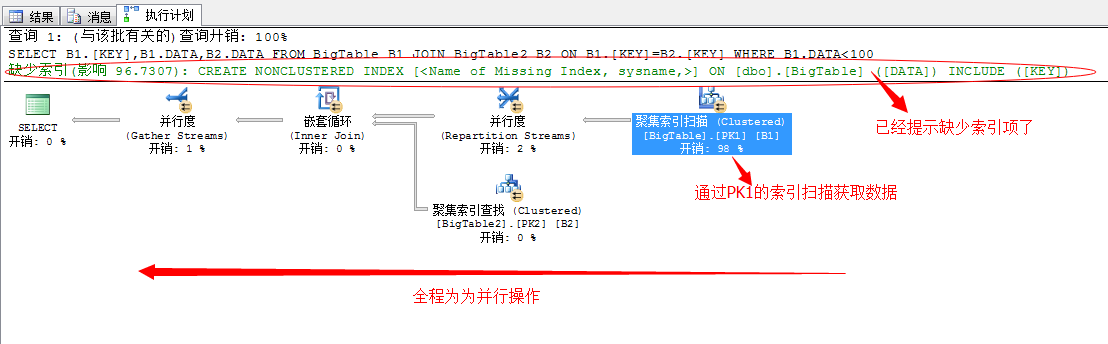
我们依次来分析这个流程,结合文本的执行计划分析更为准确,从右边依次向左分析

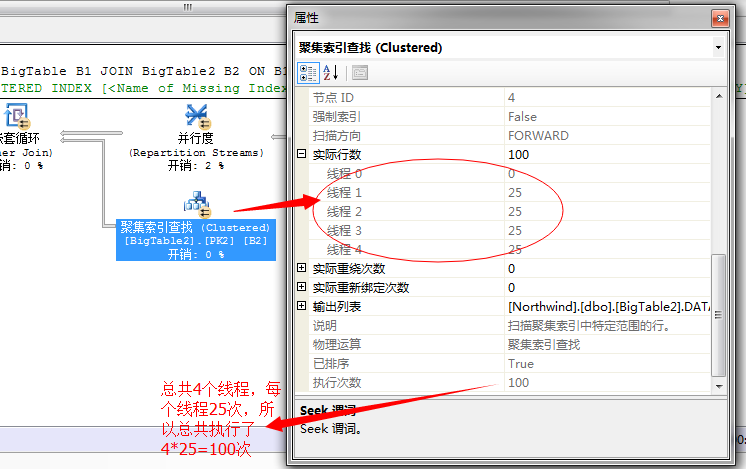
第一步,就是利用全表通过聚集索引扫描获取出数据,因为这里采用的并行的聚集索引扫描,我们来看并行的线程数和扫描数
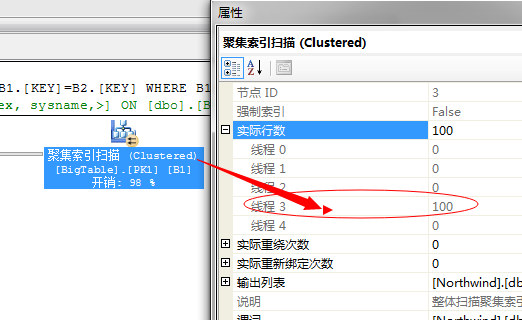
四个线程扫描,这里线程3获取出数据100行数据。
然后将这100行数据,重新分配线程,这里每个线程平均分配到25行数据
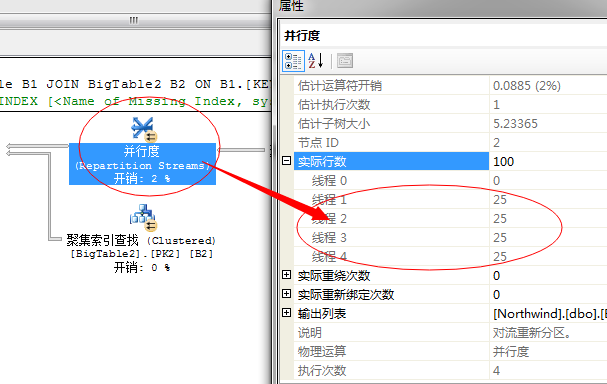
到此,我们要获取的结果已经均分成4个线程共同执行,每个线程分配了25行数据,下一步就是交给嵌套循环连接了,因为我们上面的语句中需要从BigTable2中获取数据行,所以这里选择了嵌套循环,依次扫描BigTable2获取数据。
关于嵌套循环连接运算符,可以参照我的第二篇文章。
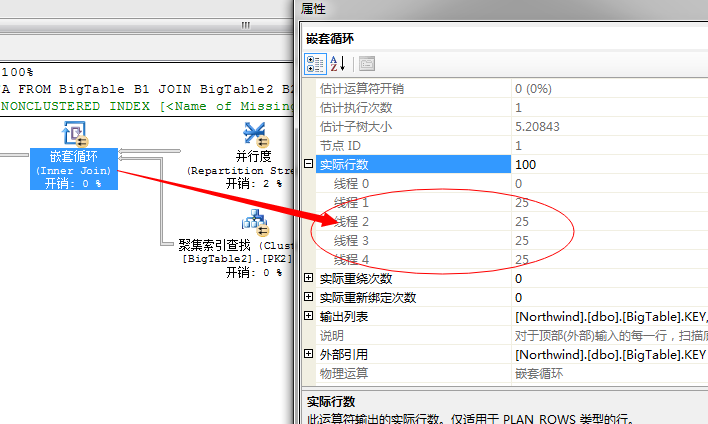
我们知道这是外表的循环数,也就是说这里会有4个线程并行执行嵌套循环。如果每个线程均分25行,数据那么内部表就要执行
4*25=100次。
然后,执行完,嵌套扫描获取结果后,下一步就是,将各个线程执行的结果通过并行运算符汇总,然后输出
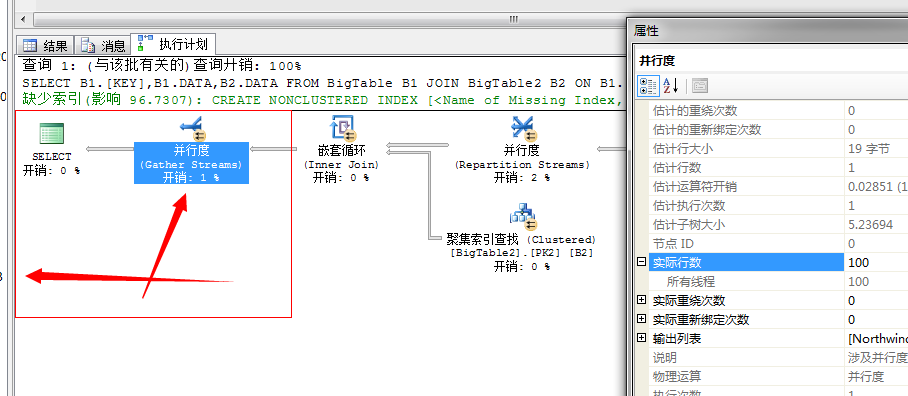
上述过程就是一个并行嵌套循环的执行流程。充分利用了四核的硬件资源。
结语
此篇文章先到此吧,文章短一点,便于理解掌握,后续关于并行操作还有一部分内容,后续文章补充吧,本篇主要介绍了查询计划中的并行运算符,下一篇我 们接着补充一部分SQL Server中的并行运算,然后分析下我们日常所写的增删改这些操作符的优化项,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。