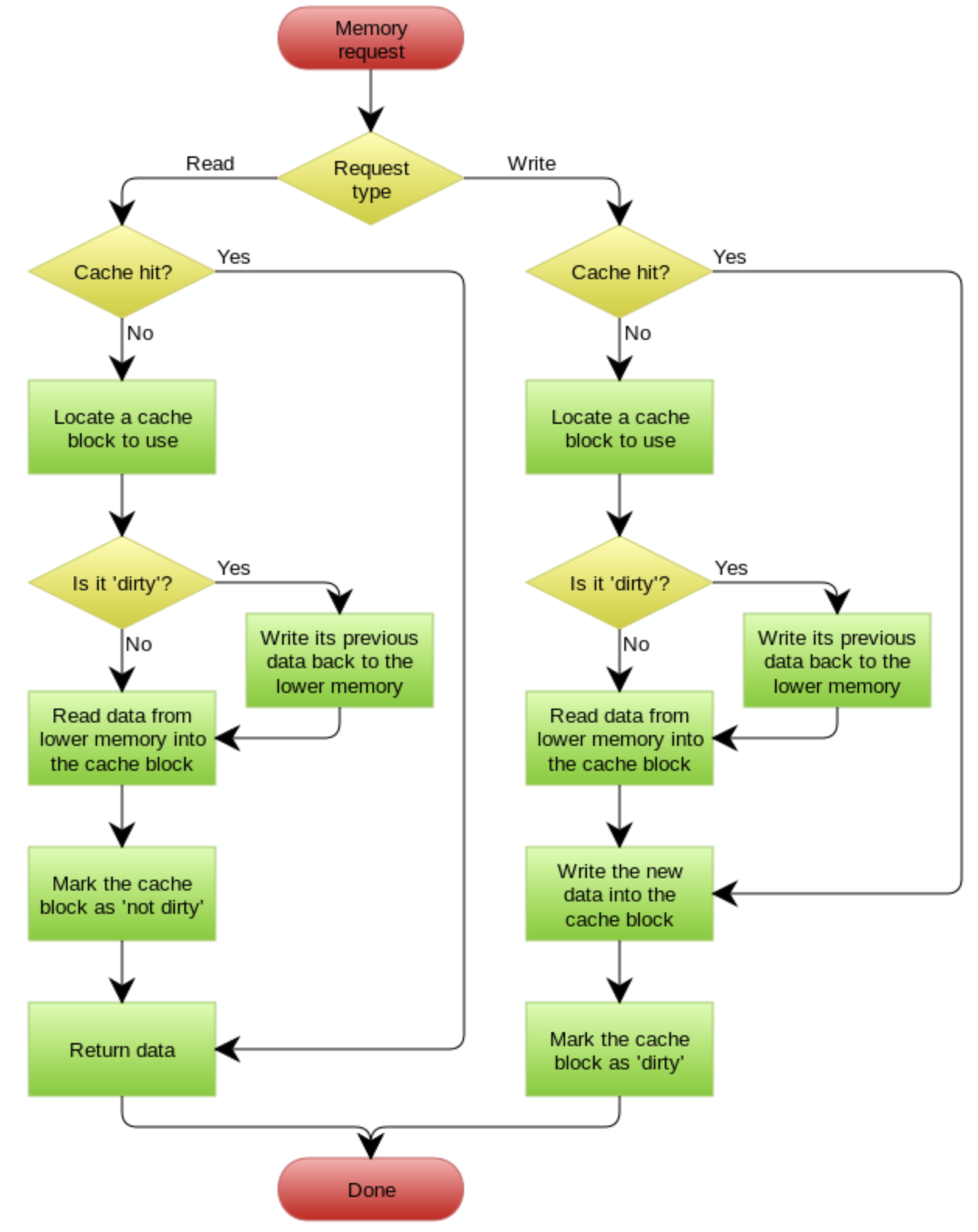
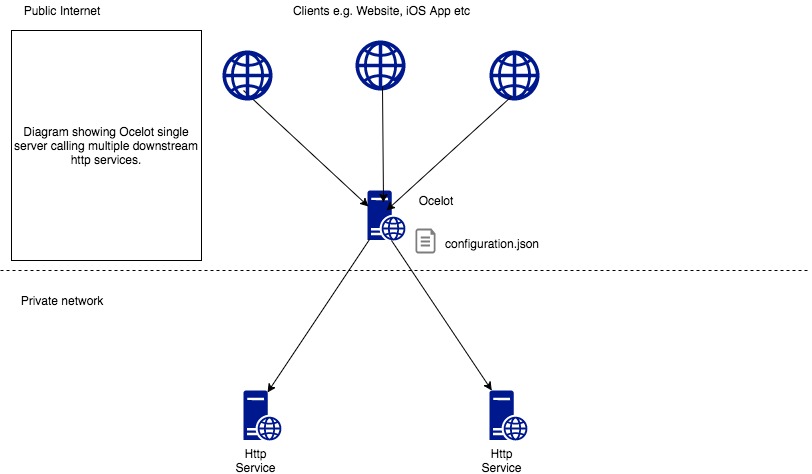
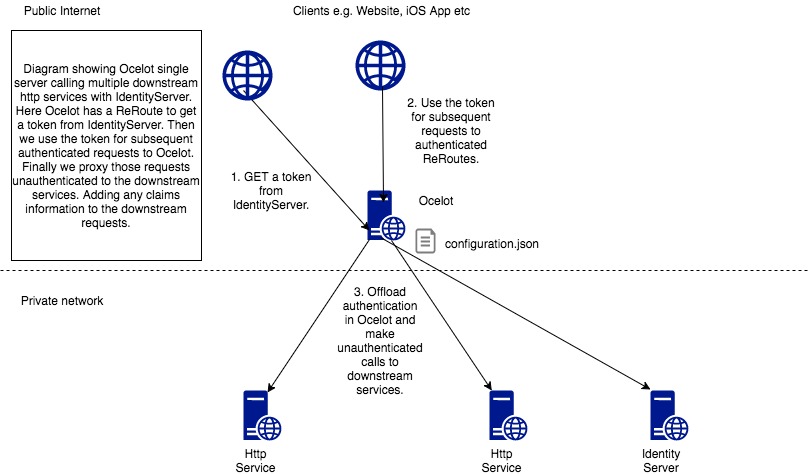
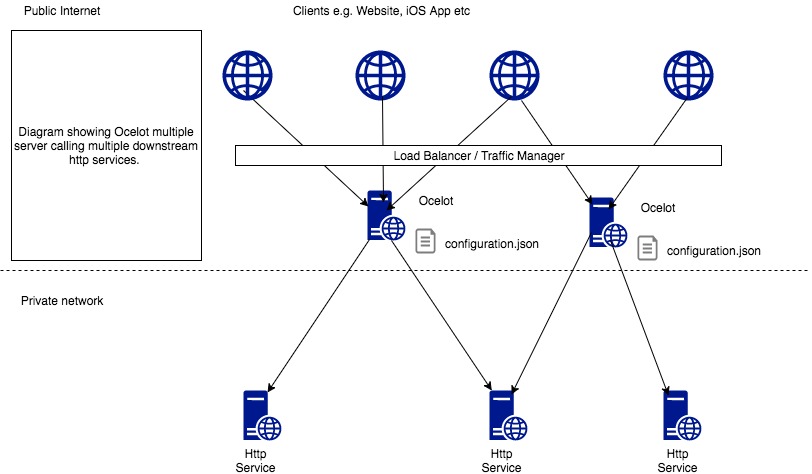
The original url of this article is https://azure.microsoft.com/en-us/overview/what-is-devops/
What is DevOps?
Learn how DevOps unifies people, process, and technology to bring better products to customers faster
- DevOps overview
- DevOps culture
- DevOps practices
- DevOps tools
- DevOps and the cloud
- Get started
- FAQ
- Free account
DevOps definition
A compound of development (Dev) and operations (Ops), DevOps is the union of people, process, and technology to continually provide value to customers.
What does DevOps mean for teams? DevOps enables formerly siloed roles—development, IT operations, quality engineering, and security—to coordinate and collaborate to produce better, more reliable products. By adopting a DevOps culture along with DevOps practices and tools, teams gain the ability to better respond to customer needs, increase confidence in the applications they build, and achieve business goals faster.
The benefits of DevOps
Teams that adopt DevOps culture, practices, and tools become high-performing, building better products faster for greater customer satisfaction. This improved collaboration and productivity is also integral to achieving business goals like these:
Accelerating time to market
Adapting to the market and competition
Maintaining system stability and reliability
Improving the mean time to recovery
DevOps and the application lifecycle
DevOps influences the application lifecycle throughout its plan, develop, deliver, and operate phases. Each phase relies on the others, and the phases are not role-specific. In a true DevOps culture, each role is involved in each phase to some extent.
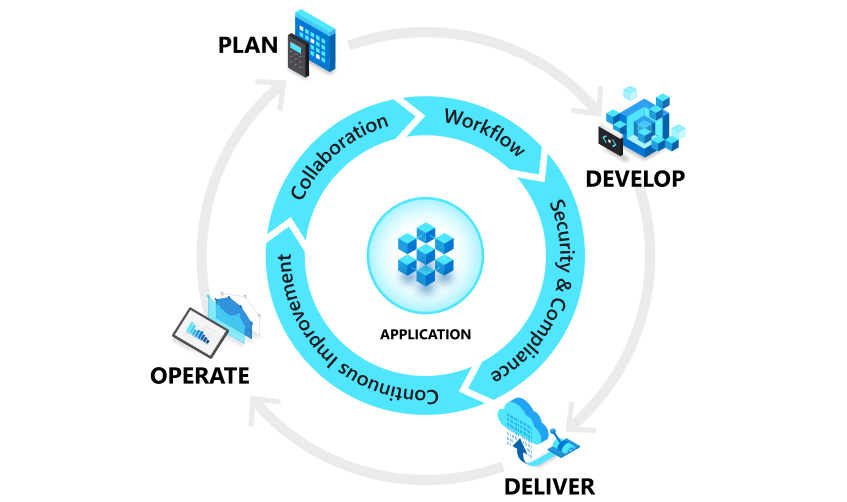
Plan
In the plan phase, DevOps teams ideate, define, and describe features and capabilities of the applications and systems they are building. They track progress at low and high levels of granularity—from single-product tasks to tasks that span portfolios of multiple products. Creating backlogs, tracking bugs, managing agile software development with Scrum, using Kanban boards, and visualizing progress with dashboards are some of the ways DevOps teams plan with agility and visibility.
Develop
The develop phase includes all aspects of coding—writing, testing, reviewing, and the integration of code by team members—as well as building that code into build artifacts that can be deployed into various environments. DevOps teams seek to innovate rapidly without sacrificing quality, stability, and productivity. To do that, they use highly productive tools, automate mundane and manual steps, and iterate in small increments through automated testing and continuous integration.
Deliver
Delivery is the process of deploying applications into production environments in a consistent and reliable way. The deliver phase also includes deploying and configuring the fully governed foundational infrastructure that makes up those environments.
In the deliver phase, teams define a release management process with clear manual approval stages. They also set automated gates that move applications between stages until they’re made available to customers. Automating these processes makes them scalable, repeatable, controlled. This way, teams who practice DevOps can deliver frequently with ease, confidence, and peace of mind.
Operate
The operate phase involves maintaining, monitoring, and troubleshooting applications in production environments. In adopting DevOps practices, teams work to ensure system reliability, high availability, and aim for zero downtime while reinforcing security and governance. DevOps teams seek to identify issues before they affect the customer experience and mitigate issues quickly when they do occur. Maintaining this vigilance requires rich telemetry, actionable alerting, and full visibility into applications and the underlying system. Continue reading “DevOps”