
前言
前面我们的几篇文章介绍了一系列关于运算符的介绍,以及各个运算符的优化方式和技巧。其中涵盖:查看执行计划的方式、几种数据集常用的连接方式、联合运算符方式、并行运算符等一系列的我们常见的运算符。有兴趣的童鞋可以点击查看。
本篇我们介绍关于子查询语句的一系列内容,子查询一般是我们形成复杂查询的一些基础性操作,所以关于子查询的应用方式就非常重要。
废话少说,开始本篇的正题。
技术准备
数据库版本为SQL Server2008R2,利用微软的一个更简洁的案例库(Northwind)进行分析。
一、独立的子查询方式
所谓的独立的子查询方式,就是说子查询和主查询没有相关性,这样带来的好处就是子查询不依赖于外部查询,所以可以独立外部查询而被评估,形成自己的执行计划执行。
举个例子
SELECT O1.OrderID,O1.Freight FROM Orders O1 WHERE O1.Freight> ( SELECT AVG(O2.Freight) FROM Orders O2 )
这句SQL执行的目标是查询订单中运费大于平均运费数的订单。
这里提取平均运费的子句就是一个完全独立的子查询,完全不依赖主查询而独立执行。同时这里我们这里利用利用一个标量计算(AVG),因此正好返回一行。
查看一下该语句的查询计划:

这个查询计划没啥好介绍的,关于子查询的执行计划形成可以参照我的第二篇:SQL Server调优系列基础篇(常用运算符总结)
不过这里需要提示一下就是,关于流聚合和计算标量形成的结果值(AVG)只包含一个结果值,所以该语句能正常的执行。
我们再来看另外一种情况
SELECT O.OrderID FROM Orders O WHERE O.CustomerID= ( SELECT C.CustomerID FROM Customers C WHERE C.ContactName=N'Maria Anders' )
该语句的也是获取名字为’Maria Anders’的顾客有多少订单。这句T-SQL语句能否执行的前提是在顾客表里存不存在同名的“’Maria Anders’”顾客,如果存在同名情况,该语句就不能正确执行,而如果恰巧只有一名顾客为’Maria Anders’,则能正常执行。
我们来分析一下对于这种执行的时候才能判断能否正确执行的SQL Server如何判断的
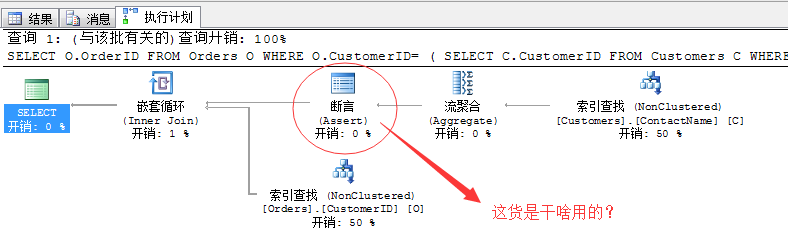
在这里出现了一个新的运算符,名字是:断言。我们用文本执行计划来查看一下,这个运算符的主要功能是什么

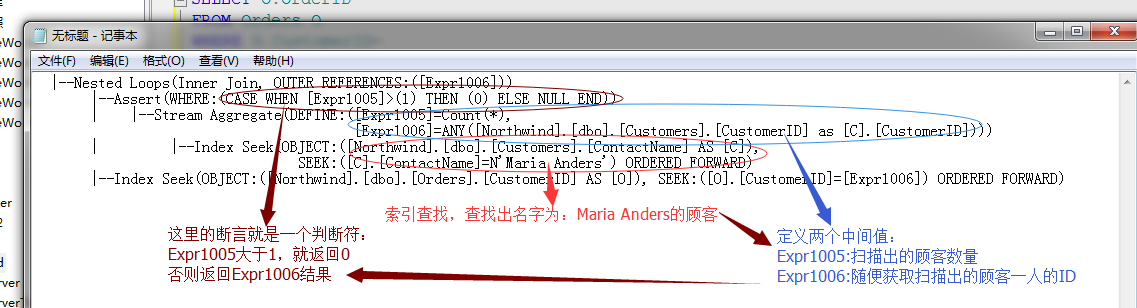
经过上面的分析,我们已经分析出了上面的“断言”运算符的作用,因为我们的子查询语句不能保证返回的结果为一行,所以,这里引入了一个断言运算符来做判断。
所以,断言的作用就是根据下文的条件,判断子查询句的查询结果是否满足主语句的查询要求。
如果,断言发现子语句不满足,就会直接报错,比如上面的Expr1005>1
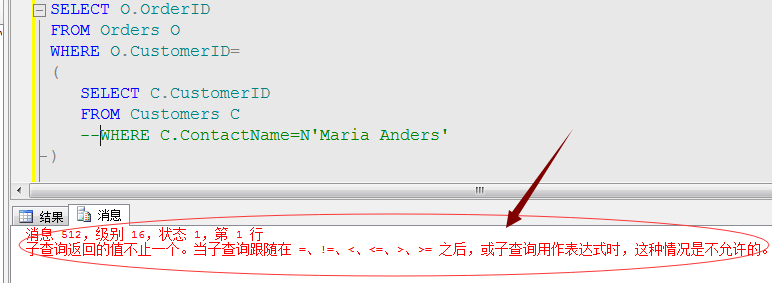
并且,断言运算符还经常用来检测其它条件是否满足,比如:约束条件、参数类型、值长度等。
其实,这里断言要解决的问题就是判断我们的筛选条件中ContactName中的值是否存在重复值的,对于这种判断相对性能消耗还是比较小的,有时候对于别的复杂的断言操作需要消耗大量资源,所以我们就可以根据适当情况情况避免断言操作。
比如,上面的语句我们可以明确的告诉SQL Server在表Customers中ContactName列就不存在重复值,它就不需要断言了。我们在上面建立一个:唯一、非聚集索引实现
CREATE UNIQUE INDEX ContactNameIndex ON Customers(ContactName) GO SELECT O.OrderID FROM Orders O WHERE O.CustomerID= ( SELECT C.CustomerID FROM Customers C WHERE C.ContactName=N'Maria Anders' ) drop index Customers.ContactNameIndex GO
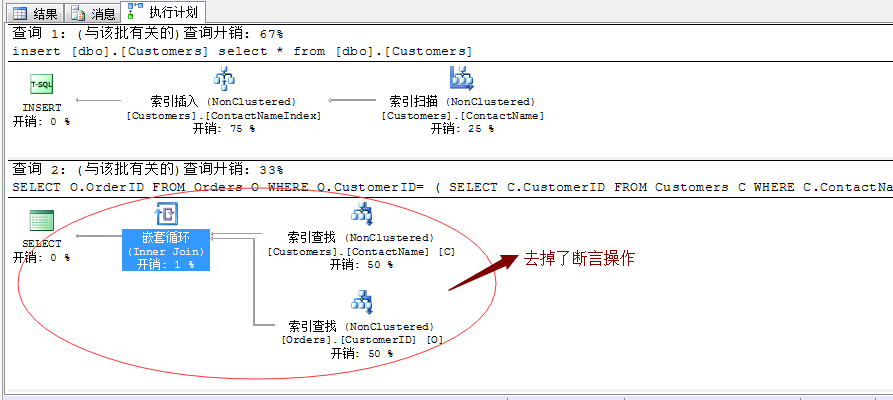
经过我们唯一非聚集索引的提示,SQL Server已经明确的知道我们的子查询语句不会返回多行的情况,所以就去掉了断言操作。
二、相关的子查询方式
相比上面的独立子查询方式,这里的相关的子查询方式相对复杂点,就是我们的子查询依赖于主查询的的结果,对于这种子查询就不能单独执行。
我们来看个这样的子查询例子
SELECT O1.OrderID FROM Orders O1 WHERE O1.Freight> ( SELECT AVG(O2.Freight) FROM Orders O2 WHERE O2.OrderDate<O1.OrderDate )
这个语句就是返回之前订单中运费量大于平均值的顶点编号。
语句很简单的逻辑,但是这里面的子查询就依赖于主查询的结果项,筛选条件中 WHERE O2.OrderDate<O1.OrderDate,所以这个子查询就不能独立运行。
我们来看一下这个语句的执行计划
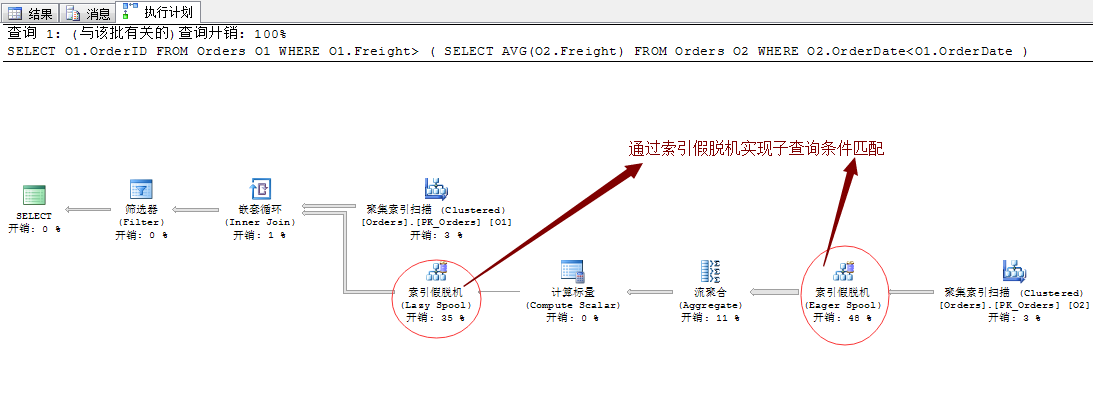
这里的查询计划有出现了一个新的运算符:索引假脱机。
其实,关于索引假脱机的作用主要是用于子查询的独立运行,因为我们知道这里的子查询的查询条件是依赖于主查询的,所以,这里想运行的话就的先提前获取出主查询的结果项,而这里获取的主查询的结果项需要一个中间表来暂存,这里暂存的工具就是:(索引池)Index Spool,而对这个索引池的操作,比如:新建、增加等操作就是上面我们所标示的“索引假脱机”了。
索引假脱机分为两种:Eager Spool和Lazy Spool,其实简单点讲就是需不需要立刻将结果存入Index Spool里面,还是通过延迟操作。
而这里形成的索引池(Index Spool)是存放于系统的临时库Tempdb中。
我们通过文本查询计划,来分析下两个索引假脱机里面的值是什么
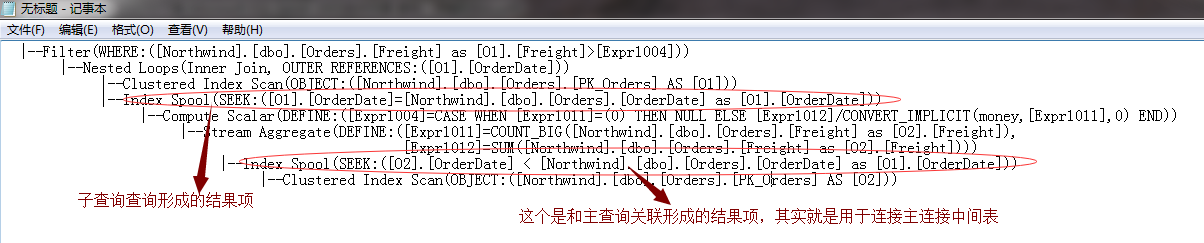
经过上面的分析,我们已经看到了,里面的Eager Spool是和主查询比较形成的结果值,因为这个必须要及时的形成,以便于子查询的进行,所以它的类型为Eager Spool,
而子查询外面的那个Index Spool为Lazy Spool,这个结果项的保存不需要那么及时了,这个保存的就是子查询的形成的结果项了,就是相对每个订单运费的平均值。
我上面的分析,希望各位看官能看懂了。
其实,关于这个Index Spool的设计的目的,完全为了就是提升性能,因为我们知道上面的查询语句每个子查询的进行,都必须回调主查询的结果,所以为了避免每次都回调,就采用 了Index Spool进行暂存,而这个Index Spool存储的位置就是Tempdb,所以Tempdb运行的快慢直接关乎这种查询语句的性能。
这也是我们为什么强调大并发的数据库搭建,建议将Tempdb库单独存放于高性能的硬件环境中。
晒晒联机丛书中关于假脱机数据运算符官方介绍:
Index Spool 物理运算符在 Argument 列中包含 SEEK:() 谓词。Index Spool 运算符扫描其输入行,将每行的副本放置在隐藏的假脱机文件(存储在 tempdb 数据库中且只在查询的生存期内存在)中,并为这些行创建非聚集索引。这样可以使用索引的查找功能来仅输出那些满足 SEEK:() 谓词的行。
如果重绕该运算符(例如通过 Nested Loops 运算符重绕),但不需要任何重新绑定,则将使用假脱机数据,而不用重新扫描输入。
跟索引脱机类似的还有一个相似的运算符:表脱机,其功能类似,表脱机存储的应该是键值列,而表脱机则是存储的是多列数据了。
来看例子
SELECT O1.OrderID,O1.Freight FROM Orders O1 WHERE O1.Freight> ( SELECT AVG(O2.Freight) FROM Orders O2 WHERE O2.CustomerID=O1.CustomerID )
这个查询和上面的类似,只不过是查询的同一个客户加入的超过所有订单运费平均值的订单。
此语句同样不是独立的子查询语句,每个子查询的结果的形成都需要依赖主查询的结果项,为了加快速度,提升性能,SQL Server会将主表查询的的结果项暂存到一张临时表中,这个表就被称为表脱机
我们来看这句话的执行计划:

这里就用到了一个表脱机的运算符,这个运算符的作用就是用来暂存后面扫描获取的结果集合,用于下面的子查询的应用
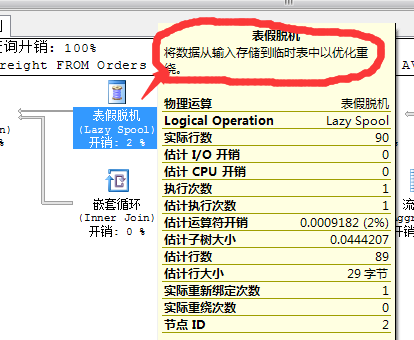
这个表脱机形成的结果项也是存储到临时库Tempdb中,所以它的应用和前面提到的索引脱机类似。
上面的执行计划中,还提到了一个新的运算符:段(Segment)
这个运算符的解释是:
Segment 既是一个物理运算符,也是一个逻辑运算符。它基于一个或多个列的值将输入集划分成多个段。这些列显示为 Segment 运算符中的参数。然后运算符每次输出一个段。
其实作用就是将结果进行汇总整理,将相同值汇聚到一起,跟排序一样,只不过这里可以对多列值进行汇聚。
我们再来看一个例子,加深 一下关于段运算的作用
SELECT CustomerID,O1.OrderID,O1.Freight FROM Orders O1 WHERE O1.Freight= ( SELECT MAX(O2.Freight) FROM Orders O2 WHERE O2.CustomerID=O1.CustomerID )
这个语句查询的是:每个顾客所产生的最大运费的订单数据。
以上语句,如果理解起来有难度,我们可以变通以下的相同逻辑的T-SQL语句,相同的逻辑
SELECT O1.CustomerID,O1.OrderID,O1.Freight
FROM Orders O1
INNER JOIN
(
SELECT CustomerID,max(Freight) Freight
FROM Orders
GROUP BY CustomerID
) AS O2
ON O1.CustomerID=O2.CustomerID
AND O1.Freight=O2.Freight
先根据客户编号分组,然后获取出最大的运费项,再关联主表获取订单信息。
以上两种语句生成的相同的查询计划:

这里我们来解释一下,SQL Server的强大之处,也是段运算符使用的最佳方式。
本来这句话要实现,按照逻辑需要有一个嵌套循环连接,参照上面的方式,使用表脱机的方式进行数据的获取。
但是,我们这句话获取的结果项是每个顾客的最大运费的订单明细项,而且CustomerID列作为输出项,所以这里采用了,先按照运费列(Freight)排序,
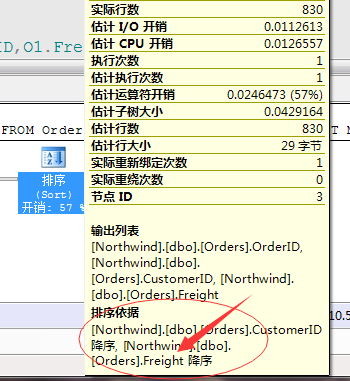
然后采用段运算符进行将每个顾客相同的数据汇聚到一起,然后再输出每个顾客的前一列(TOP 1)获取的就是最每个顾客的运费最大的订单项。
省去了任何的表假脱机、索引假脱机、关联连接等一系列复杂的操作。
SQL Server看来这种智能化的操作还是挺强的。
我们再来分析SQL Server关于子查询这块的智能特性,因为经过上面的分析通过对比,相关的子查询语句在运行时需要更多的消耗:
1、有时候需要通过索引假脱机(Index Spool)、表脱机(Table Spool)进行中间结果项的暂存,而这一过程的中间项需要创建、增加、删除、销毁等操作都需要消耗大量的内存和CPU
2、关于相关子查询中以上提到的中间项的形成都是位于Tempdb临时库中,有时候会增大Tempdb的空间,增加Tempdb库的消耗、页争用等问题。
所以,要避免上面的问题,最好的方式是避免使用相关子查询,尽量使用独立子查询进行操作。
当然,SQL Server同样提供了自动转换的功能,智能的去分析语句,避免相关的子查询操作进行:
来看一个稍差的写法:
SELECT o.OrderID FROM Orders O WHERE EXISTS ( SELECT c.CustomerID FROM Customers C WHERE C.City=N'Londom' AND C.CustomerID=O.CustomerID )
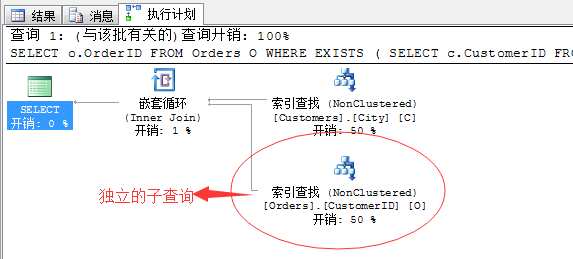
上面的语句,我们写的是相关的子查询操作,但是在执行计划中形成的确实独立的子查询,这样从而避免相关的子查询所带来的性能消耗。
其实上面语句,相对好的写法是如下
SELECT o.OrderID FROM Orders O WHERE O.CustomerID IN ( SELECT c.CustomerID FROM Customers C WHERE C.City=N'Londom' )
这样所形成的就是完全独立的子查询,这也是SQL Server要执行的意图。所以这个语句形成的查询计划是和上面的查询计划一样。
这里的优化全部得益于SQL Server的智能化。
但是我们在写语句的时候,需要自己了解,掌握好,这样才能写出高效的T-SQL语句。
结语
本篇篇幅有点长,但是介绍的子查询内容也还不是很全,后续慢慢的补充上,我们写的SQL语句中很多都涉及到子查询,所以这块应用还是挺普遍的。到本 篇文章关于日常调优的T-SQL中的查询语句经常用到的一些运算符基本介绍全了,当然,还有一些别的增删改一系列的运算符,这些日常生活中我们一般不采用 查询计划调优,后续我们的文章会将这些运算符也添加上,以供参考之用。
在完成本系列关于查询计划相关的调优之后,我打算将数据库有关统计信息这块也做一个详细的分析介绍。因为统计信息是支撑SQL Server评估最优执行计划的最重要的决策点,
所以统计信息的重要性不言而喻。有兴趣的童鞋可以提前关注。
关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。