
前言
上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤、筛选条件分析、索引项优化等信息。
本篇我们分析在我们运行的过程中几个关键指标值的检测。
通过这些指标值来分析语句的运行问题,并且分析其优化方式。
通过本篇我们可以学习到调优中经常利用的几个利器!
废话少说,开始本篇的正题。
技术准备
数据库版本为SQL Server2008R2,利用微软的一个更简洁的案例库(Northwind)进行分析。
利器一、IO统计
通过这个IO统计能为我们分析出当前查询语句所要扫描的数据页的数量。这里面有几个重要的概念,我们依次分析。
方法很简单,一行代码搞定:
SET STATISTICS IO ON
来看个例子
SET STATISTICS IO ON GO SELECT * FROM Person.Contact

这里可以看到这个语句对于数据表的操作次数,基于数据页的扫描项。
所谓的数据页就是数据库的底层数据存储方式,SQL Server以数据页的形式存储表行数据。每个数据页为8K,
8K=8192字节-96字节(页头)-36字节(行偏移)=8060字节
也就说一个数据页存储的纯数据内容为8060字节。
我们依次来解释上面出现几个读取的概念:
逻辑读
表示处理查询所需要访问页的总数。也就是说要完成一个查询语句需要读取的数据页的总数。
这里的数据页有可能来自内存,也有可能来自硬盘读取。
物理读
这个就是说来自硬盘读取的数据页数。我们知道SQL Server每次都会将读取的数据页尽可能存在于内存中,以方便下一次直接读取,提升读取速度。
所以在这里关于存储于内存中的数据页下次访问的概率,提出了一个指标:缓存命中率
缓存命中率=(逻辑读—物理读)/逻辑读
提出这个指标的提出其实就是为了衡量内存中缓存的数据页的有效性。比如:假如缓存与内存中的数据页就使用一次就不使用了,对于这种就应该及时从内存中清除掉,毕竟对于内存资源来说是非常昂贵的。应该用它来缓存命中率高的数据页。
预读
预读其实就是SQL语句在优化的时候预先读取到内存中的数据页数。这个预先读取的数据页是提前评估出来的,也就是上一篇我们文章中介绍的查询优化器要做的事情。
当然,这些预读的数据页有时候不是所有的都要用到,但是它基本能涵盖到查询用到的数据页。
这里要提示一下,预读数据是通过另外一个线程进行读取的和语句优化线程非用同一线程,并行运行,目的是快速获取数据,提升查询获取的速度。
从这个指标我们可以分析出很多问题,来举个例子:
我们新添加一张测试表,脚本如下
--执行下面脚本新生成一张表 SELECT * INTO NewOrders FROM Orders GO --新增加一列 ALTER TABLE NewOrders ADD Full_Details CHAR(2000) NOT NULL DEFAULT 'full details' GO
然后利用如下脚本来看下这张表的大小
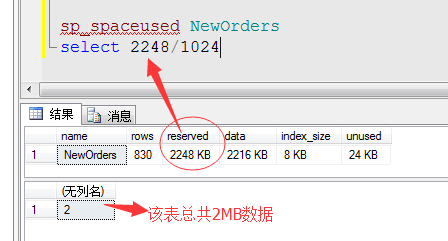
EXEC sp_spaceused NewOrders,TRUE GO

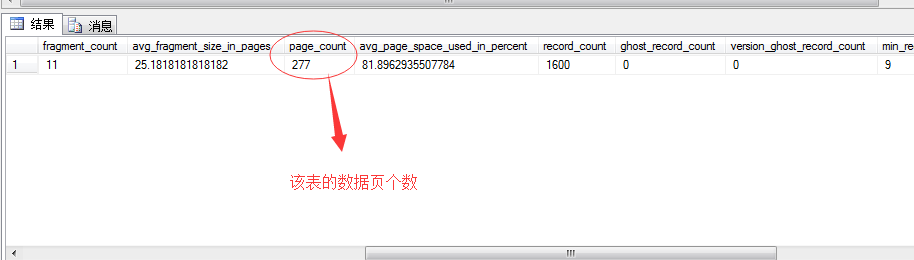
我们可以看到这张表数据页的总大小为2216KB,我们知道一页为8KB,可以推断出这个表的数据页有:
2216(数据页总大小)/8(一个数据页大小)=277页
也就是说这个数据表有277个数据页。
当然,我们也可以通过如下DMV视图来查看该页的数据页数
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID('Northwind'),object_id('NewOrders'),NULL,NULL,'detailed')
经过上面的分析,
我们可以推测,在查询这张表做全表扫描的时候,理论的数据页的逻辑读数就应该为277次
通过如下语句验证下
--先清空缓存数据,生产机慎用 DBCC DROPCLEANBUFFERS SET STATISTICS IO ON SELECT * FROM NewOrders
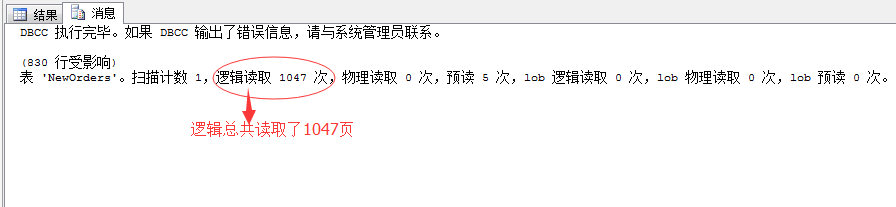
我去…
这里的逻辑读取为1047页,和我们上面的推断277页不相符…擦…神马原因!!!
这里就是我们要分析的数据页Forwarded record现象造成的。因为我们在新建立的表,在后面新添加的一列数据:Full_Details,类型为CHAR(2000)的数据列,当数据行中的变长列增长使得原有页无法容纳下数据行时,数据将会移动到新的页中,并在原位置留下一个指向新页的指针,这就是所谓的: Forwarded record
我们可以通过如下DMV视图,查看该表的Forwarded Record形成的页有多少
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(N'Northwind'),object_id('NewOrders'),NULL,NULL,'detailed')

纠正一下:上图的770数据页为Forwarded Record页,非拆分页的概念(感谢院友 wy123 指出)。
看到了,这里的Forwarded Record页为770页,那么我们就可以推测出我们的逻辑读数量来了
277(原数据页)+770(Forwarded Record页)=1047页
所以上面的我们的问题就分析出原因了。
我们通过此表也展示了一个Forwarded Record页的问题:会影响查询性能。
解决的方式很多种,最简单的方式就是重建聚集索引。
CREATE CLUSTERED INDEX orderID_C ON NewOrders(OrderID) GO DROP INDEX NewOrders.orderID_C GO SET STATISTICS IO ON SELECT * FROM NewOrders GO

通过IO统计项,除了可以分析出上面的Forwarded Record页造成的碎片外,更重要的地方使用来对比不同查询语句之间的读取次数,通过降低读取的次数来优化语句。
关于预读的情况,我们在前面已经分析了,其数据时通过另外一个线程在T-SQL查询语句优化的时候进行数据的预加载。
所以这个线程在预读数据的时候其实是有一个参考值的,根据这个参考值读取出来的数据才能保证大部分数据是有用的,也就是提高上面提到的缓存命中率。
关于这个参考值,我分析了下,其实是分为两中情况分析的。
首先、如果是数据表为堆表,SQL Server获取的方式只能通过全表扫描了。而此方式为了避免重复读取,增加消耗,所以一次的预读并非读取一个数据页,而是一段物理上的连续64个页
来看联机丛书的官方解释:
预读机制允许数据库引擎从一个文件中读取最多 64 个连续页 (512KB)。该读取作为缓冲区高速缓存中相应数量(可能是非相邻的)缓冲区的一次散播-聚集读取来执行。如果此范围内的任何页在缓冲区高速缓存中已存 在,当读取完成时,所读取的相应页将被放弃。如果相应页在缓存中已存在,也可以从任何一端“裁剪”页的范围。
所以,如果我们的表在物理上不是连续页,那么读取次数就不好怎么确定了。
我们来看个堆表的例子
SET STATISTICS IO ON --新建个测试表 SELECT * INTO NewOrders_TEST FROM NewOrders SELECT * FROM NewOrders_TEST

这里预读的次数为8次,所以我估计底层的数据页肯定不是连续的。所以造成了多出了3次。
我们可以DBCC IND()进行查询下,来验证下我的推断。
DBCC IND('Northwind','NewOrders_TEST',1)
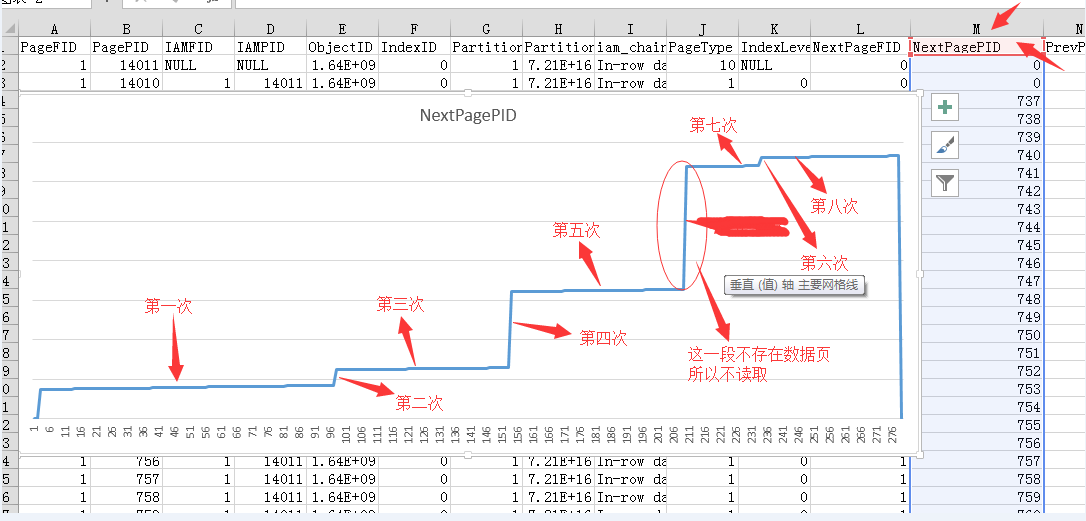
数据信息比较多,我将其粘贴到Excel中,然后做了一个折线图,其中涂掉的部分其实是没有数据页的,所以不会产生一次读取。
关于读取顺序标示的也有点问题,不过确定的总数肯定是8次…..
希望这种方式,各位看官能看懂了…希望我也表述明白了。
其次、如果表非堆表,也就是说存在聚集索引项,那么好了,SQL Server很轻松的找到了它预读的参考依据:统计信息。
并且,我们知道数据以B-Tree数存储,读取的数据页都存在与叶子节点。所以基本没有了什么连续读取的感念。
一个叶子节点就是一个数据页,一个数据页就是一次预读。
来看个例子:
我们将上面的表添加上聚集索引项,再一次清空缓存,执行查询,脚本如下
CREATE CLUSTERED INDEX NewOrders_TESTIndex ON NewOrders_TEST(OrderID) GO SELECT * FROM NewOrders_TEST

这里添加了聚集索引,SQL Server仿佛一下看到了救星,根据统计信息,预读数据就可以。
所以如果统计信息有错误,就造成了预读的乱读取….然后严重降低了缓存命中率…..然后严重增加了内存中换出换入的速度….增加了CPU….
好了,咱们继续文章,上面我们提到的这个预读数据行,可以在如下DMV中查到。
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(N'Northwind'),object_id('NewOrders_TEST'),NULL,NULL,'detailed')
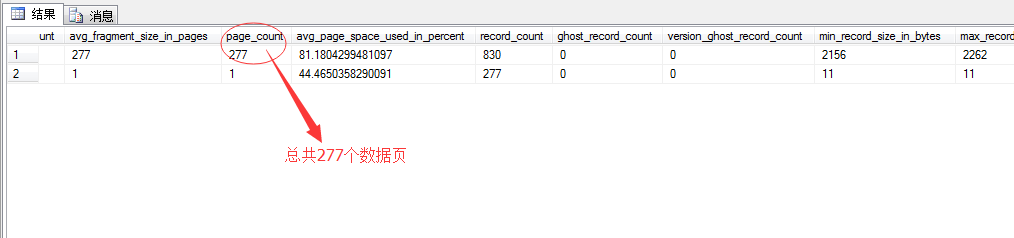
从这个DMV视图中可以看到这种表统计信息为277个数据页,所以形成了277次预读。
但是,事实这个数据表是279页,也就是说统计的信息有问题,造成了少读读取了2个数据页,而为了弥补这个统计过失就出现了2次物理读,重新从硬盘中获取。
利器二、时间统计
关于时间统计这个很简单,就是统计T-SQL执行语句执行时间项,包括CPU占用时间、语句编译时间、语句执行总时间等项。
使用方法也很简单,一行代码
SET STATISTICS TIME ON

通过这个参数,可以分析出以上信息,其作用主要是用来对比查询语句调优中的执行时间,我们的目标就是降低执行时间。
举例:我们通过开启时间统计,来对比下,上面的查询语句,在第一次运行和以后运行(数据已经缓存)的时间对比,了解下缓存的重要性
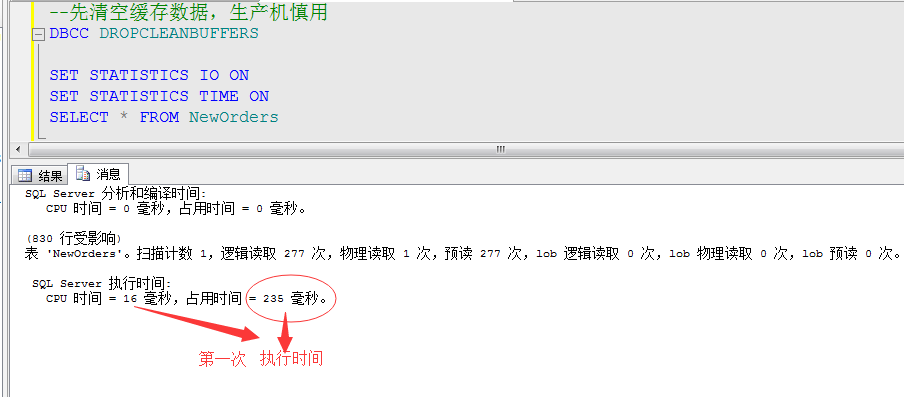
再次执行的时间
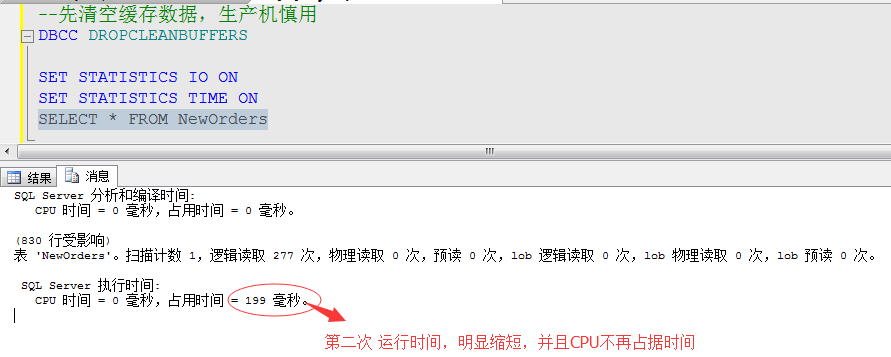
缓存追踪
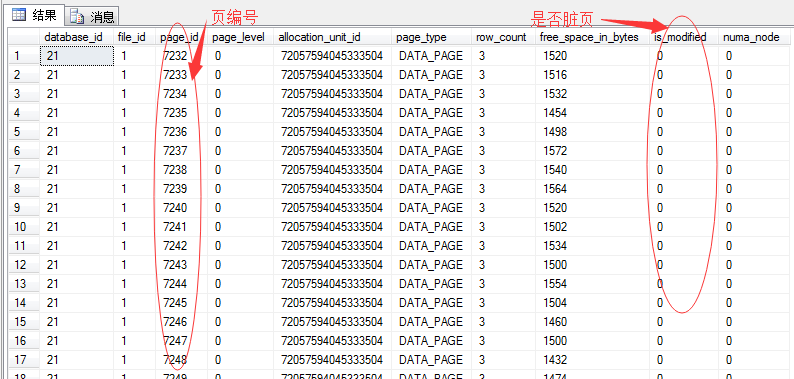
当然我们也可以再深入一点,如果想查看该部分数据在内存中缓存的明细,可以通过如下DMV脚本查看
SELECT * FROM sys.dm_os_buffer_descriptors WHERE DB_NAME(database_id)='Northwind' AND page_type='DATA_PAGE' ORDER BY page_id
也可以通过该DMV分析出各个库在内存中占据的大小比例,脚本如下:
--清除缓存
dbcc dropcleanbuffers
--查看缓存内容中在内存大小
SELECT COUNT(*)*8/1024 as 'Cached Size(MB)'
,CASE database_id
WHEN 32767 THEN 'ResourceDB'
ELSE DB_NAME(database_id)
END AS 'Database'
FROM sys.dm_os_buffer_descriptors
GROUP BY DB_NAME(database_id),database_id
ORDER BY 'Cached Size(MB)' DESC
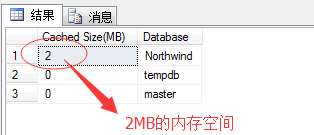
经过这次查询,这张表已经全部缓存到内存里了,因为整张表总共就2MB的大小
文章已经有点长度了…先到此吧。