YARP is a library to help create reverse proxy servers that are high-performance, production-ready, and highly customizable. Right now it’s still in preview, but please provide us your feedback by going to the GitHub repository.
We found a bunch of internal teams at Microsoft who were either building a reverse proxy for their service or had been asking about APIs and tech for building one, so we decided to get them all together to work on a common solution, this project.
YARP is built on .NET using the infrastructure from ASP.NET and .NET (.NET Core 3.1 and .NET 5.0). The key differentiator for YARP is that it’s been designed to be easily customized and tweaked via .NET code to match the specific needs of each deployment scenario.
We expect YARP to ship as a library, project template, and a single-file exe, to provide a variety of choices for building a robust, performant proxy server. Its pipeline and modules are designed so that you can then customize the functionality for your needs. For example, while YARP supports configuration files, we expect that many users will want to manage the configuration programmatically based on their own configuration management system, YARP will provide a configuration API to enable that customization in-proc. YARP is designed with customizability as a primary scenario rather than requiring you to break out to script or rebuild the library from source.
支持(仅列举部分):
Header Routing
Proxy routes specified in config or via code must include at least a path or host to match against. In addition to these, a route can also specify one or more headers that must be present on the request.
Authentication and Authorization
The reverse proxy can be used to authenticate and authorize requests before they are proxied to the destination servers. This can reduce load on the destination servers, add a layer of protection, and ensure consistent policies are implemented across your applications.
Cross-Origin Requests (CORS)
The reverse proxy can handle cross-origin requests before they are proxied to the destination servers. This can reduce load on the destination servers and ensure consistent policies are implemented across your applications.
Session Affinity:
Session affinity is a mechanism to bind (affinitize) a causally related request sequence to the destination handled the first request when the load is balanced among several destinations. It is useful in scenarios where the most requests in a sequence work with the same data and the cost of data access differs for different nodes (destinations) handling requests. The most common example is a transient caching (e.g. in-memory) where the first request fetches data from a slower persistent storage into a fast local cache and the others work only with the cached data thus increasing throughput.
Load Balancing
Whenever there are multiple healthy destinations available, YARP has to decide which one to use for a given request. YARP ships with built-in load-balancing algorithms, but also offers extensibility for any custom load balancing approach.
Transforms
When proxying a request it’s common to modify parts of the request or response to adapt to the destination server’s requirements or to flow additional data such as the client’s original IP address. This process is implemented via Transforms. Types of transforms are defined globally for the application and then individual routes supply the parameters to enable and configure those transforms. The original request objects are not modified by these transforms, only the proxy requests.
Destinations Health Checks
In most of the real-world systems, it’s expected for their nodes to occasionally experience transient issues and go down completely due to a variety of reasons such as an overload, resource leakage, hardware failures, etc. Ideally, it’d be desirable to completely prevent those unfortunate events from occurring in a proactive way, but the cost of designing and building such an ideal system is generally prohibitively high. However, there is another reactive approach which is cheaper and aimed to minimizing a negative impact failures cause on client requests. The proxy can analyze each nodes health and stop sending client traffic to unhealthy ones until they recover. YARP implements this approach in the form of active and passive destination health checks.
The article copyed from https://ocelot.readthedocs.io
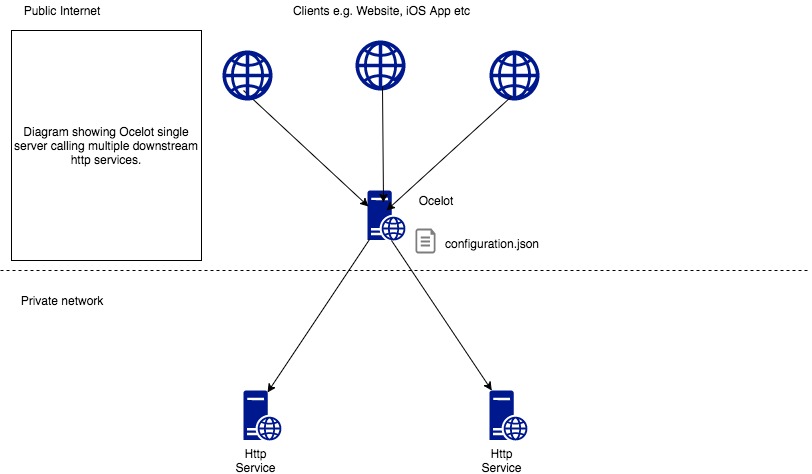
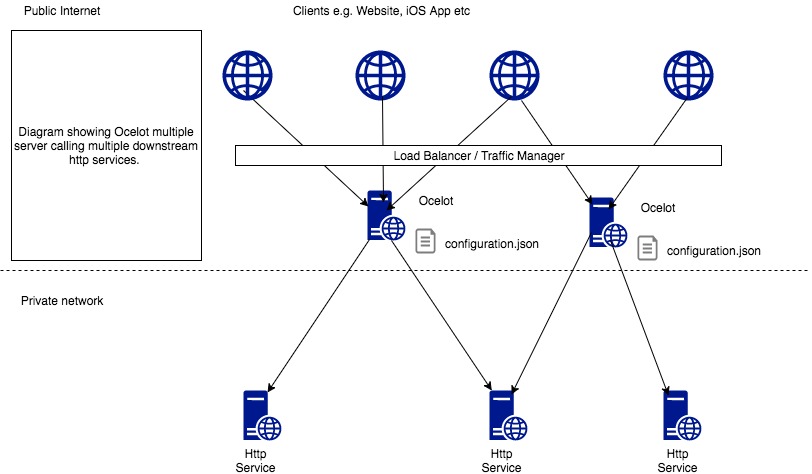
Ocelot is aimed at people using .NET running a micro services / service orientated architecture that need a unified point of entry into their system.
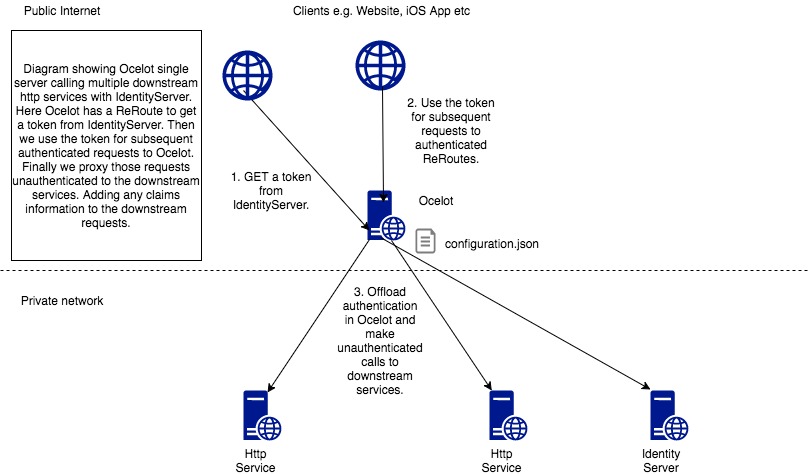
In particular I want easy integration with IdentityServer reference and bearer tokens.
Ocelot is a bunch of middlewares in a specific order.
Ocelot manipulates the HttpRequest object into a state specified by its configuration until it reaches a request builder middleware where it creates a HttpRequestMessage object which is used to make a request to a downstream service. The middleware that makes the request is the last thing in the Ocelot pipeline. It does not call the next middleware. There is a piece of middleware that maps the HttpResponseMessage onto the HttpResponse object and that is returned to the client. That is basically it with a bunch of other features.
The following are configurations that you use when deploying Ocelot.
There are several kinds of OData payload, includes service document, model metadata, feed, entry, entity references(s), complex value(s), primitive value(s). OData Core library is designed to write and read all these payloads.We’ll go through each kind of payload here. But first, we’ll set up the neccessary code that is common to all kind of payload.Class ODataMessageWriter is the entrance class to write the OData Payload.To construct an ODataMessageWriter instance, you’ll need to provide an IODataResponseMessage, or IODataRequestMessage, depends on if you are writing a response or a request.OData Core library provides no implementation of these two interfaces, because it is different in different scenario.In this tutoria, we’ll use the InMemoryMessage.cs.
We’ll use the model set up in the EDMLIB section.
IEdmModel model = builder
.BuildAddressType()
.BuildCategoryType()
.BuildCustomerType()
.BuildDefaultContainer()
.BuildCustomerSet()
.GetModel();
Then set up the message to write the payload.
MemoryStream stream = new MemoryStream();
InMemoryMessage message = new InMemoryMessage() {Stream = stream};
Create the settings:
ODataMessageWriterSettings settings = new ODataMessageWriterSettings();
Now we are ready to create the ODataMessageWriter instance:
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage) message, settings, model);
After we write the payload, we can inspect into the memory stream wrapped in InMemoryMessage to check what is written.
Here is the whole program that use SampleModelBuilder and InMemoryMessage to write metadata payload:
IEdmModel model = builder
.BuildAddressType()
.BuildCategoryType()
.BuildCustomerType()
.BuildDefaultContainer()
.BuildCustomerSet()
.GetModel();
MemoryStream stream = new MemoryStream();
InMemoryMessage message = new InMemoryMessage() {Stream = stream};
ODataMessageWriterSettings settings = new ODataMessageWriterSettings();
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage) message, settings, model);
writer.WriteMetadataDocument();
string output =Encoding.UTF8.GetString(stream.ToArray());
Console.WriteLine(output);
Now we’ll go through on each kind of payload.
Write metadata
Write metadata is simple, just use WriteMetadataDocument method in ODataMessageWriter.
writer.WriteMetadataDocument();
Please be noticed that this API only works when: 1. Writting response message, that means when constructing the ODataMessageWriter, you mut supply IODataRequestMessage. 2. A model is supplied when constructing ODataMessageWriter.
So the following two examples won’t work.
ODataMessageWriter writer = new ODataMessageWriter((IODataRequestMessage) message, settings, model);
writer.WriteMetadataDocument();
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage) message);
writer.WriteMetadataDocument();
Write service document
To write a service document, first create a ODataServiceDocument instance, which will contains all the neccessary information in a service document, that include, entity set, singleton and function import.
In this example, we create a service document that contains two entity sets, one singleton and one function import.
ODataServiceDocument serviceDocument = new ODataServiceDocument();
serviceDocument.EntitySets = new []
{
new ODataEntitySetInfo
{
Name = "Customers",
Title = "Customers",
Url = new Uri("Customers", UriKind.Relative),
},
new ODataEntitySetInfo
{
Name = "Orders",
Title = "Orders",
Url = new Uri("Orders", UriKind.Relative),
},
};
serviceDocument.Singletons = new[]
{
new ODataSingletonInfo
{
Name = "Company",
Title = "Company",
Url = new Uri("Company", UriKind.Relative),
},
};
serviceDocument.FunctionImports = new[]
{
new ODataFunctionImportInfo
{
Name = "GetOutOfDateOrders",
Title = "GetOutOfDateOrders",
Url = new Uri("GetOutOfDateOrders", UriKind.Relative),
},
};
Then let’s call WriteServiceDocument method to write it.
writer.WriteServiceDocument(serviceDocument);
However, this would not work. An ODataException will threw up said that “The ServiceRoot property in ODataMessageWriterSettings.ODataUri must be set when writing a payload.” This is because a valid service document will contains a context url reference to the metadata url, which need to be told in ODataMessageWriterSettings.
This service root informaiton is provided in ODataUri.ServiceRoot, as this code shows.
ODataMessageWriterSettings settings = new ODataMessageWriterSettings();
settings.ODataUri = new ODataUri()
{
ServiceRoot = new Uri("http://services.odata.org/V4/OData/OData.svc/")
};
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage) message, settings);
writer.WriteServiceDocument(serviceDocument);
As you can see, you don’t need to provide model to write service document.
It is a little work to instantiate the service document instance and set up the entity sets, singletons and function imports. Actually, the EdmLib provided a useful API which can generate a service document instance from model. The API is named GenerateServiceDocument, and defined as an extension method on IEdmModel.
All the entity sets, singletons and function imports whose IncludeInServiceDocument attribute is set to true in the model will be in the generated service document. And according to the spec, only those function import without any parameter should set its IncludeInServiceDocument attribute to true.
And as WriteMetadata API, WriteServiceDocument works only when it is writing a response message.
Besides API WriteServiceDocument, there is another API called WriteServiceDocumentAsync in ODataMessageWriter class. It is an async version of WriteServiceDocument, so you can call it in async way.
A lot of API in writer and reader provides async version of API, they all work as a async complement of the API that without Async suffix.
Write Feed
Collection of entities is called feed in OData Core Library. Unlike metadata or service document, you must create another writer on ODatMessageWriter to write the feed. The library is designed to write feed in an streaming way, which means the entry is written one by one.
Feed is represented by ODataFeed class. To write a feed, following information are needed: 1. The service root, which is defined by ODataUri. 2. The model, as construct parameter of ODataMessageWriter. 3. Entity set and entity type information.
Here is how to write an empty feed.
ODataMessageWriterSettings settings = new ODataMessageWriterSettings();
settings.ODataUri = new ODataUri()
{
ServiceRoot = new Uri("http://services.odata.org/V4/OData/OData.svc/")
};
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage)message, settings, model);
IEdmEntitySet entitySet = model.FindDeclaredEntitySet("Customers");
ODataWriter odataWriter = writer.CreateODataFeedWriter(entitySet);
ODataFeed feed = new ODataFeed();
odataWriter.WriteStart(feed);
odataWriter.WriteEnd();
Line 4 give the service root, line 6 give the model, and line 10 give the entity set and entity type information.
The output contains a context url in the output, which is based on the service root you provided in ODataUri, and the entity set name. There is also a value which is an empty collection, where will hold the entities if there is any.
There is another way to provide the entity set and entity type information, through ODataFeedAndEntrySerializationInfo, and in this no model is needed.
ODataMessageWriterSettings settings = new ODataMessageWriterSettings();
settings.ODataUri = new ODataUri()
{
ServiceRoot = new Uri("http://services.odata.org/V4/OData/OData.svc/")
};
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage)message, settings);
ODataWriter odataWriter = writer.CreateODataFeedWriter();
ODataFeed feed = new ODataFeed();
feed.SetSerializationInfo(new ODataFeedAndEntrySerializationInfo()
{
NavigationSourceName = "Customers",
NavigationSourceEntityTypeName = "Customer"
});
odataWriter.WriteStart(feed);
odataWriter.WriteEnd();
When writting feed, you can provide a next page, which is used in server driven paging.
ODataFeed feed = new ODataFeed();
feed.NextPageLink = new Uri("Customers?next", UriKind.Relative);
odataWriter.WriteStart(feed);
odataWriter.WriteEnd();
The output will contains a next link before the value collection.
The reader API is almost like the writer API, so you can expect the symmetry here.First, we’ll set up the neccessary code that is common to all kind of payload.Class ODataMessageReader is the entrance class to read the OData Payload.To construct an ODataMessageReader instance, you’ll need to provide an IODataResponseMessage, or IODataRequestMessage, depends on if you are reading a response or a request.OData Core library provides no implementation of these two interfaces, because it is different in different scenario.In this tutoria, we’ll still use the InMemoryMessage.cs.
We’ll still use the model set up in the EDMLIB section.
IEdmModel model = builder
.BuildAddressType()
.BuildCategoryType()
.BuildCustomerType()
.BuildDefaultContainer()
.BuildCustomerSet()
.GetModel();
Then set up the message to read the payload.
MemoryStream stream = new MemoryStream();
InMemoryMessage message = new InMemoryMessage() {Stream = stream};
Create the settings:
ODataMessageReaderSettings settings = new ODataMessageReaderSettings();
Now we are ready to create the ODataMessageReader instance:
ODataMessageReader reader = new ODataMessageReader((IODataResponseMessage) message, settings);
We’ll use the code in the first part to write the payload, and in this section use the reader to read the payload. After write the payload, we should set the Position of MemoryStream to zero.
stream.Position = 0;
Here is the whole program that use SampleModelBuilder and InMemoryMessage to first write then read metadata payload:
IEdmModel model = builder
.BuildAddressType()
.BuildCategoryType()
.BuildOrderType()
.BuildCustomerType()
.BuildDefaultContainer()
.BuildOrderSet()
.BuildCustomerSet()
.GetModel();
MemoryStream stream = new MemoryStream();
InMemoryMessage message = new InMemoryMessage() { Stream = stream };
ODataMessageWriterSettings writerSettings = new ODataMessageWriterSettings();
ODataMessageWriter writer = new ODataMessageWriter((IODataResponseMessage)message, writerSettings, model);
writer.WriteMetadataDocument();
stream.Position = 0;
ODataMessageReaderSettings settings = new ODataMessageReaderSettings();
ODataMessageReader reader = new ODataMessageReader((IODataResponseMessage)message, settings);
IEdmModel modelFromReader = reader.ReadMetadataDocument();
Now we’ll go through on each kind of payload.
Read metadata
Read metadata is simple, just use ReadMetadataDocument method in ODataMessageReader.
reader.ReadMetadataDocument();
Just like writing metadata, this API only works when reading response message, that means when constructing the ODataMessageReader, you must supply IODataResponseMessage.
Read service document
Read service document is through the ReadServiceDocument API.
ODataMessageReaderSettings readerSettings = new ODataMessageReaderSettings();
ODataMessageReader reader = new ODataMessageReader((IODataResponseMessage)message, readerSettings, model);
ODataServiceDocument serviceDocumentFromReader = reader.ReadServiceDocument();
And as ReadMetadata API, ReadServiceDocument works only when it is reading a response message.
Besides API ReadServiceDocument, there is another API called ReadServiceDocumentAsync in ODataMessageReader class. It is an async version of ReadServiceDocument, so you can call it in async way.
To read a feed, you must create another reader on ODataFeedReader to read the feed. The library is designed to read feed in an streaming way, which means the entry is read one by one.
Here is how to read a feed.
ODataMessageReader reader = new ODataMessageReader((IODataResponseMessage)message, readerSettings, model);
ODataReader feedReader = reader.CreateODataFeedReader(entitySet, entitySet.EntityType());
while (feedReader.Read())
{
switch (feedReader.State)
{
case ODataReaderState.FeedEnd:
ODataFeed feedFromReader = (ODataFeed)feedReader.Item;
break;
case ODataReaderState.EntryEnd:
ODataEntry entryFromReader = (ODataEntry)feedReader.Item;
break;
}
}
Read Entry
To read a top level entry, use ODataMessageReader.CreateEntryReader. Other than that, there is no different compared to read feed.
ODataMessageReader reader = new ODataMessageReader((IODataResponseMessage)message, readerSettings, model);
ODataReader feedReader = reader.CreateODataEntryReader(entitySet, entitySet.EntityType());
while (feedReader.Read())
{
switch (feedReader.State)
{
case ODataReaderState.FeedEnd:
ODataFeed feedFromReader = (ODataFeed)feedReader.Item;
break;
case ODataReaderState.EntryEnd:
ODataEntry entryFromReader = (ODataEntry)feedReader.Item;
break;
}
}
1.3 Use ODataUriParser
This post is intended to guide you through the UriParser for OData V4, which is released within ODataLib V6.0 and later.You may have already read the following posts about OData UriParser in ODataLib V5.x:
The main reference document for UriParser is the URL Conventions specification. The ODataUriParser class is its main implementation in ODataLib.
The ODataUriParser class has two main functionalities:
Parse resource path
Parse query options
We’ve also introduced the new ODataQueryOptionParser class in ODataLib 6.2+, in case you do not have the full resource path and only want to parse the query options only. The ODataQueryOptionParser shares the same API signature for parsing query options, you can find more information below.
Using ODataUriParser
The use of ODataUriParser class is easy and straightforward, as we mentioned, we do not support static methods now, we will begin from creating an ODataUriParser instance.
ODataUriParser has only one constructor:
public ODataUriParser(IEdmModel model, Uri serviceRoot, Uri fullUri);
Parameters:
model is the Edm model the UriParser will refer to; serviceRoot is the base Uri for the service, which could be a constant for certain service. Note that serviceRoot must be an absolute Uri; fullUri is the full request Uri including query options. When it is an absolute Uri, it must be based on the serviceRoot, or it can be a relative Uri. In the following demo we will use the model from OData V4 demo service , and create an ODataUriParser instance.
Uri serviceRoot = new Uri("http://services.odata.org/V4/OData/OData.svc");
IEdmModel model = EdmxReader.Parse(XmlReader.Create(serviceRoot + "/$metadata"));
Uri fullUri = new Uri("http://services.odata.org/V4/OData/OData.svc/Products");
ODataUriParser parser = new ODataUriParser(model, serviceRoot, fullUri);
Parsing Resource Path
You can use the following API to parse resource path:
Uri fullUri = new Uri("http://services.odata.org/V4/OData/OData.svc/Products(1)");
ODataUriParser parser = new ODataUriParser(model, serviceRoot, fullUri);
ODataPath path = parser.ParsePath();
You don’t need to pass in resource path as parameter here, because the constructor has taken the full Uri.
The ODataPath holds the enumeration of path segments for resource path. All path segments are represented by classes derived from ODataPathSegment.
In our demo, the resource Path in the full Uri is Products(1), then the result ODataPath would contain two segments: one EntitySetSegment for EntitySet named Products, and the other KeySegment for key with integer value “1” .
Parsing Query Options
ODataUriParser supports parsing following query options: $select, $expand, $filter, $orderby, $search, $top, $skip, and $count.
For the first five, the parsing result is an instance of class XXXClause, which represents the query option as an Abstract Syntax Tree (with semantic information bound). Note that $select and $expand query options are merged together in one SelectExpandClause class. The latter three all have primitive type value, and the parsing result is the corresponding primitive type wrapped by Nullable class.
For all query option parsing results, the Null value indicates the corresponding query option is not specified in the request URL.
Here is a demo for parsing the Uri with all kinds of query options (please notice that value of skip would be null as it is not specified in the request Uri) :
The data structure for SelectExpandClause, FilterClause, OrdeyByClause have already been presented in the two previous articles mentioned at the top of this post. Here I’d like to talk about the newly introduced SearchClause.
SearchClause contains tree representation of the $search query. The detailed rule of $search query option can be found here. In general, the search query string can contain search terms combined with logic keywords: AND, OR and NOT.
All search terms are represented by SearchTermNode, which is derived from SingleValueNode. SearchTermNode has one property named Text, which contains the original word or phrases.
SearchClause’s Expression property holds the tree structure for $search. If the $search contains single word, the Expression would be set to that SearchTermNode. But when $search is a combination of various term and logic keywords, the Expression would also contains nested BinaryOperatorNode and UnaryOperatorNode.
For example, if the query option $search has the value “a AND b”, the result expression (syntax tree) would have the following structure:
SearchQueryOption
Expression = BinaryOperatorNode
OperationKind = BinaryOperatorKind.And
Left = SearchTermNode
Text = a
Right = SearchTermNode
Text = b
Using ODataQueryOption Parser
There may be some cases that you already know the query context information but does not have the full request Uri. The ODataUriParser does not seems to be available as it will always require the full Uri, then the user would have to fake one.
In ODataLib 6.2 we shipped a new Uri parser that targets at query options only, it requires the model and type information be provided through its constructor, then it could be used for query options parsing as same as ODataUriParser.
The constructor looks like this:
public ODataQueryOptionParser(IEdmModel model, IEdmType targetEdmType, IEdmNavigationSource targetNavigationSource, IDictionary<string, string> queryOptions);
Parameters (here the target object indicates what resource path was addressed, see spec):
model is the model the UriParser will refer to; targetEdmType is the type query options apply to, it is the type of target object; targetNavigationSource is the EntitySet or Singleton where the target comes from, it is usually the NavigationSource of the target object; queryOptions is the dictionary containing the key-value pairs for query options.
Here is the demo for its usage, it is almost the same as the ODataUriParser:
Data Source=TORCL;User Id=myUsername;Password=myPassword;
Example:
Data Source=localhost:1521/orcl; User Id=scott; Password=scott;
Using integrated security
Data Source=TORCL;Integrated Security=SSPI;
Using ODP.NET without tnsnames.ora
Data Source=(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=MyHost)(PORT=MyPort)))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=MyOracleSID)));
User Id=myUsername;Password=myPassword;
Using the Easy Connect Naming Method (aka EZ Connect)
The easy connect naming method enables clients to connect to a database without any configuration.
Data Source=username/password@//myserver:1521/my.service.com;
Port 1521 is used if no port number is specified in the connection string.
Make sure that EZCONNECT is enabled in the sqlnet.ora file. NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
‘//’ in data source is optional and is there to enable URL style hostname values
Easy Connect Naming Method to connect to an Instance
This one does not specify a service or a port.
Data Source=username/password@myserver//instancename;
Easy Connect Naming Method to connect to a dedicated server instance
This one does not specify a service or a port.
Data Source=username/password@myserver/myservice:dedicated/instancename;
Other server options: SHARED, POOLED (to use instead of DEDICATED). Dedicated is the default.
Specifying Pooling parameters
By default, connection pooling is enabled. This one controls the pooling mechanisms. The connection pooling service creates connection pools by using the ConnectionString property to uniquely identify a pool.
Data Source=myOracle;User Id=myUsername;Password=myPassword;Min Pool Size=10;
Connection Lifetime=120;Connection Timeout=60;Incr Pool Size=5;Decr Pool Size=2;
The first connection opened creates the connection pool. The service initially creates the number of connections defined by the Min Pool Size parameter.
The Incr Pool Size attribute defines the number of new connections to be created by the connection pooling service when more connections are needed.
When a connection is closed, the connection pooling service determines whether the connection lifetime has exceeded the value of the Connection Lifetime attribute. If so, the connection is closed; otherwise, the connection goes back to the connection pool.
The connection pooling service closes unused connections every 3 minutes. The Decr Pool Size attribute specifies the maximum number of connections that can be closed every 3 minutes.
Restricting Pool size
Use this one if you want to restrict the size of the pool.
Data Source=myOracle;User Id=myUsername;Password=myPassword;Max Pool Size=40;
Connection Timeout=60;
The Max Pool Size attribute sets the maximum number of connections for the connection pool. If a new connection is requested, but no connections are available and the limit for Max Pool Size has been reached the connection pooling service waits for the time defined by the Connection Timeout attribute. If the Connection Timeout time has been reached, and there are still no connections available in the pool, the connection pooling service raises an exception indicating that the request has timed-out.
Disable Pooling
Data Source=myOracle;User Id=myUsername;Password=myPassword;Pooling=False;
Using Windows user authentication
Oracle can open a connection using Windows user login credentials to authenticate database users.
Data Source=myOracle;User Id=/;
If the Password attribute is provided, it is ignored.
Operating System Authentication is not supported in a .NET stored procedure.
Privileged Connections
Oracle allows database administrators to connect to Oracle Database with either SYSDBA or SYSOPER privileges.
Data Source=myOracle;User Id=myUsername;Password=myPassword;DBA Privilege=SYSDBA;
SYSOPER is also valid for the DBA Privilege attribute.
Runtime Connection Load Balancing
Optimizes connection pooling for RAC database by balancing work requests across RAC instances.
Data Source=myOracle;User Id=myUsername;Password=myPassword;Load Balancing=True;
This feature can only be used against a RAC database and only if pooling is enabled (default).