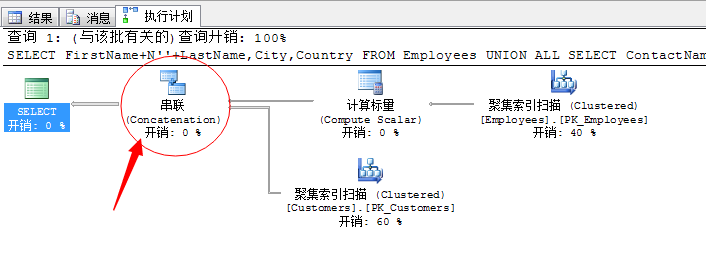
1.区:
区是SQL Server 中管理空间的基本单位。
一个区是八个物理上连续的页(即 64 KB), 所有页都存储在区中, 这意味着 SQL Server 数据库中每 MB 有 16 个区。 一旦一个区段已满, 下一条数据Sql server将分配一个区段空间, 防止每次添加都要分配空间.
2.页(Page):
页是SQL Server 中数据存储的基本单位, 它是区段的分配单元, 一页8K, 它下面就是数据行了, 但每页的行数不定, 这取决于数据行的大小.
数据库中的数据文件(.mdf 或 .ndf)分配的磁盘空间可以从逻辑上划分成页(从 0 到 n 连续编号)。磁盘 I/O 操作在页级执行。也就是说,SQL Server 每次读取或写入数据的最少数据单位是数据页。
每页的开头是 96 字节的标头,用于存储有关页的系统信息。此信息包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元 ID。
在 SQL Server 中,页的大小为 8 KB。这意味着 SQL Server 数据库中每 MB 有 128 页。依次类推。根据数据库的文件大小,我们可以算出数据库有多少数据页。
3.页的类型: 数据页, 索引页, Blob页等等.
4.行: 因为行存于页中,因此, 一行的大小通常最多8K(8060字符, 一页的上限), 一行最大列数为1024列(字段).
如果是varchar(max), text, image时, 可以跨越多页, 一行最大2GB, 此时, 原始的行用来存放指针及其它列.
5.全文目录: 虽然和sql server在一起, 但实际上该目录是独立存放在磁盘上的.
6.索引: 是与表或视图关联的磁盘上的结构,可以加快从表或视图中检索行的速度。
它包含由表或视图中的一列或多列生成的键。这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关联的行。
7.索引的类型:聚集, 非聚集.
另外还有唯一索引, 唯一索引确保索引键不包含重复的值,因此,表或视图中的每一行在某种程度上是唯一的。
聚集索引和非聚集索引都可以是唯一索引。
8.聚集索引: 根据数据行的键值在表或视图中排序和存储这些数据行。
每个表只能有一个聚集索引,因为数据行本身只能按一个顺序排序。
只有当表包含聚集索引时,表中的数据行才按排序顺序存储。如果表具有聚集索引,则该表称为聚集表。
如果表没有聚集索引,则其数据行存储在一个称为堆的无序结构中。
即聚集表是有聚集索引的表,堆是没有聚集索引的表。
索引视图与聚集表具有相同的存储结构。
聚集索引的叶节点就是实际的数据页。
聚集索引的平均大小大约为表大小的5%左右。
9.非聚集索引:
每个表最多可以有249个非聚集索引.
10.索引的维护:每当修改了表数据后,都会自动维护表或视图的索引。
11.索引和约束: 对表列定义了 PRIMARY KEY 约束和 UNIQUE 约束时,会自动创建索引。
下面摘自MSDN:
页和区
SQL Server 中数据存储的基本单位是页。为数据库中的数据文件(.mdf 或 .ndf)分配的磁盘空间可以从逻辑上划分成页(从 0 到 n 连续编号)。磁盘 I/O 操作在页级执行。也就是说,SQL Server 读取或写入所有数据页。
区是八个物理上连续的页的集合,用来有效地管理页。所有页都存储在区中。
页
在 SQL Server 中,页的大小为 8 KB。这意味着 SQL Server 数据库中每 MB 有 128 页。每页的开头是 96 字节的标头,用于存储有关页的系统信息。此信息包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元 ID。
下表说明了 SQL Server 数据库的数据文件中所使用的页类型。
| 页类型 |
内容 |
| Data |
当 text in row 设置为 ON 时,包含除 text、 ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 和 xml 数据之外的所有数据的数据行。 |
| Index |
索引条目。 |
| Text/Image |
大型对象数据类型:
- text、 ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 和 xml 数据。
数据行超过 8 KB 时为可变长度数据类型列:
- varchar、nvarchar、varbinary 和 sql_variant
|
| Global Allocation Map、Shared Global Allocation Map |
有关区是否分配的信息。 |
| Page Free Space |
有关页分配和页的可用空间的信息。 |
| Index Allocation Map |
有关每个分配单元中表或索引所使用的区的信息。 |
| Bulk Changed Map |
有关每个分配单元中自最后一条 BACKUP LOG 语句之后的大容量操作所修改的区的信息。 |
| Differential Changed Map |
有关每个分配单元中自最后一条 BACKUP DATABASE 语句之后更改的区的信息。 |
在数据页上,数据行紧接着标头按顺序放置。页的末尾是行偏移表,对于页中的每一行,每个行偏移表都包含一个条目。每个条目记录对应行的第一个字节与页首的距离。行偏移表中的条目的顺序与页中行的顺序相反。

大型行支持
行不能跨页,但是行的部分可以移出行所在的页,因此行实际可能非常大。页的单个行中的最大数据量和开销是 8,060 字节 (8 KB)。但是,这不包括用 Text/Image 页类型存储的数据。包含 varchar、nvarchar、varbinary 或 sql_variant 列的表不受此限制的约束。当表中的所有固定列和可变列的行的总大小超过限制的 8,060 字节时,SQL Server 将从最大长度的列开始动态将一个或多个可变长度列移动到 ROW_OVERFLOW_DATA 分配单元中的页。每当插入或更新操作将行的总大小增大到超过限制的 8,060 字节时,将会执行此操作。将列移动到 ROW_OVERFLOW_DATA 分配单元中的页后,将在 IN_ROW_DATA 分配单元中的原始页上维护 24 字节的指针。如果后续操作减小了行的大小,SQL Server 会动态将列移回到原始数据页。有关详细信息,请参阅行溢出数据超过 8 KB。
区
区是管理空间的基本单位。一个区是八个物理上连续的页(即 64 KB)。这意味着 SQL Server 数据库中每 MB 有 16 个区。
为了使空间分配更有效,SQL Server 不会将所有区分配给包含少量数据的表。SQL Server 有两种类型的区:
- 统一区,由单个对象所有。区中的所有 8 页只能由所属对象使用。
- 混合区,最多可由八个对象共享。区中八页的每页可由不同的对象所有。
通常从混合区向新表或索引分配页。当表或索引增长到 8 页时,将变成使用统一区进行后续分配。如果对现有表创建索引,并且该表包含的行足以在索引中生成 8 页,则对该索引的所有分配都使用统一区进行。

行内数据
小到中等大小的大值类型(varchar(max)、nvarchar(max)、varbinary(max) 和 xml)和大型对象 (LOB) 数据类型(text、ntext 和 image)都可以存储在数据行中。该行为可以通过在 sp_tableoption 系统存储过程中使用以下两个选项来控制:用于大值类型的 large value types out of row 选项,以及用于大型对象类型的 text in row 选项。这两个选项最适用于这样的表:其中上述任意一种数据类型的数据值通常在一个单元中读/写,并且引用表的大多数语句都将引用此类数据。在行内存储的数据不一定有用,这取决于使用情况或工作负荷特征。
除非 text in row 选项设置为 ON 或特定的行内限制,否则 text、ntext 或 image 字符串都将是在数据行外存储的大型字符或二进制字符串(最多 2 GB)。数据行只包括一个 16 字节的文本指针,该指针指向一个内部指针构成的树的根节点。这些指针映射存储字符串片段的页。有关 text、ntext 或 image 字符串存储的详细信息,请参阅使用 Text 和 Image 数据。
可以为包含 LOB 数据类型列的表设置 text in row 选项。还可以指定 text in row 选项限制,范围从 24 到 7,000 字节。
同样,除非 large value types out of row 选项设置为 ON,否则会尽可能将 varchar(max)、nvarchar(max)、varbinary(max) 和 xml 列存储在数据行内。如果如此设置,则可以的话 SQL Server 数据库引擎将尝试容纳此特定值,否则会将其推到行外。如果 large value types out of row 设置为 ON,则上述值将存储在行外而只有 16 字节的文本指针存储在记录中。
| 注意 |
| 当 large value types out of row 设置为 OFF 时,用于大型值数据类型的最大行内存储量设置为 8,000 字节。与 text in row 选项不同,您不能指定表中列的行内限制。 |
将表配置为直接在数据行中存储大型值类型或大型对象数据类型时,如果存在以下情况之一,实际的列值都将存储在行内:
- 字符串的长度小于为 text、ntext 和 image 列指定的限制值。
- 数据行中有足够的可用空间容纳字符串。
当大型值类型或大型对象数据类型列值存储在数据行中时,数据库引擎不必访问单独的页或页集来读/写字符或二进制字符串。这便使读/写行内字符串的速度与读/写大小受限制的 varchar、nvarchar 或 varbinary 字符串的速度大致一样。同样,当值存储在行外时,数据库引擎将引发读/写附加页。
对于大型对象数据类型,如果存储字符串所需的空间比 text in row 选项限制或行中的可用空间大,则本应存储在指针树根节点中的指针集将存储在行中。如果存在以下情况之一,指针将存储在行中:
- 存储指针所需的空间量比 text in row 选项限制指定的空间量小。
- 数据行中有足够的可用空间容纳指针。
当指针从根节点移至行本身时,数据库引擎不需要使用根节点。这样便可以在读/写字符串时不必访问页。从而可以提高性能。
如果使用根节点,它们将存储为 LOB 页中的一个字符串片段,并且最多可以包含 5 个内部指针。数据库引擎需要行具有 72 字节的空间来存储行内字符串的五个指针。如果 text in row 选项为 ON 或 large value types out of row 选项为 OFF 时行中没有足够的空间来容纳指针,数据库引擎可能必须分配一个 8K 的页来容纳它们。如果值的数据长度超过 40,200 字节,则需要 5 个以上的行内指针,此时只有 24 字节存储在主行中,而其他数据页被分配在 LOB 存储空间中。
当大型字符串存储在行中时,它们将与可变长度字符串的存储方式相似。数据库引擎将对列按大小以降序排序,并将值推到行外,直到剩余的列容纳在数据页 (8K) 中。
行溢出数据超过 8 KB
一个表中的每一行最多可以包含 8,060 字节。在 SQL Server 2008 中,对于包含 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型列的表,可以放宽此限制。其中每列的长度仍必须在 8,000 字节的限制内,但是它们的总宽可以超过 8,060 字节的限制。创建和修改 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型的列以及更新或插入数据时,此限制适用于上述列。
当合并每行超过 8060 字节的 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型的列时,请注意下列事项:
- 超过 8,060 字节的行大小限制可能会影响性能,因为 SQL Server 仍保持每页 8 KB 的限制。当合并 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型的列超过此限制时,SQL Server 数据库引擎 将把最大宽度的记录列移动到 ROW_OVERFLOW_DATA 分配单元的另一页上,而在原始页上保留一个 24 字节指针。如果更新操作使记录变长,大型记录将被动态移动到另一页。如果更新操作使记录变短,记录可能会移回 IN_ROW_DATA 分配单元中的原始页。此外,执行查询和其他选择操作(例如,对包含行溢出数据的大型记录进行排序或合并)将延长处理时间,因为这些记录将同步处理,而不是 异步处理。因此,当要设计的表中包含多个 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型的列时,请考虑可能溢出的行的百分比,以及可能查询这些溢出数据的频率。如果可能需要经常查询行溢出数据中的许多行,请考虑对表格进行规范化处理,以使某些列移动到另一个表中。然后可以在异步 JOIN 操作中执行查询。
- 对于 varchar、nvarchar、varbinary、sql_variant 或 CLR 用户定义类型的列,单个列的长度仍然必须在 8000 字节的限制之内。只有它们的合并长度可以超过表的 8060 字节的行限制。
- 其他数据类型列的和(包括 char 和 nchar 数据)必须在 8,060 字节的行限制之内。大型对象数据也不受 8,060 字节行限制的制约。
- 聚集索引的索引键不能包含在 ROW_OVERFLOW_DATA 分配单元中具有现有数据的 varchar 列。如果对 varchar 列创建了聚集索引,并且在 IN_ROW_DATA 分配单元中存在现有数据,则对该列执行的将数据推送到行外的后续插入或更新操作将会失败。有关分配单元的详细信息,请参阅表组织和索引组织。
- 可以包括包含行溢出数据的列,作为非聚集索引的键列或非键列。
- 对 于使用稀疏列的表,记录大小限制为 8,018 字节。转换后的数据加上现有记录数据超过 8,018 字节时,会返回 MSSQLSERVER ERROR 576。列在稀疏和非稀疏类型之间转换时,数据库引擎会保留当前记录数据的副本。这样,记录所需的存储会临时加倍。
- 若要获得有关可能包含行溢出数据的表或索引的信息,请使用 sys.dm_db_index_physical_stats 动态管理函数。