
常见的字段类型选择
约束与索引
每张表必须有主键
•每张表必须有主键,用于强制实体完整性
•单表只能有一个主键(不允许为空及重复数据)
•尽量使用单字段主键
不允许使用外键
•外键对插入,更新的性能有影响,需要检查主外键约束
•数据完整性由程序控制
索引设计准则
不要给选择性低的字段创建单列索引
充分利用唯一索引
唯一索引给SQL Server提供了确保某一列绝对没有重复值的信息,当查询分析器通过唯一索引查找到一条记录则会立刻退出,不会继续查找索引
•表索引数不超过6个, 表索引数不超过6个(这个规则只是携程DBA经过试验之后制定的。。。)
•索引加快了查询速度,但是却会影响写入性能
•一个表的索引应该结合这个表相关的所有SQL综合创建,尽量合并
•组合索引的原则是,过滤性越好的字段越靠前
•索引过多不仅会增加编译时间,也会影响数据库选择最佳执行计划
SQL查询
禁止在数据库做复杂运算
禁止使用SELECT *
•禁止在索引列上使用函数或计算
禁止在索引列上使用函数或计算
假设在字段Col1上建有一个索引,则下列场景将可以使用到索引:
[Col1]=3.14
[Col1]>100
[Col1] BETWEEN 0 AND 99
[Col1] LIKE ‘abc%’
[Col1] IN(2,3,5,7)
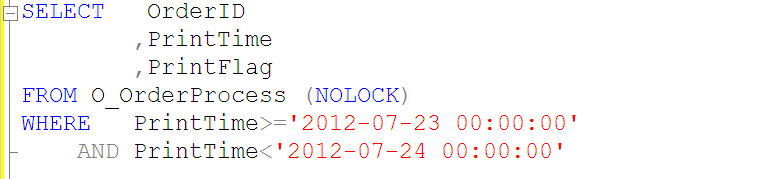
像上面这样的查询,将无法用到O_OrderProcess表上的PrintTime索引
LIKE查询的索引问题
禁止使用游标
禁止使用触发器
•触发器对应用不透明(应用层面都不知道会什么时候触发触发器,发生也也不知道,感觉莫名其秒)
禁止在查询里指定索引
With(index=XXX)( 在查询里我们指定索引一般都用With(index=XXX) )
变量/参数/关联字段类型必须与字段类型一致(这是我之前不太关注的)
避免类型转换额外消耗的CPU,引起的大表scan尤为严重
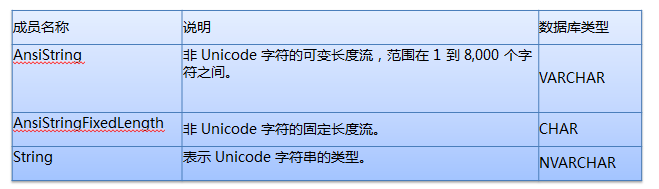
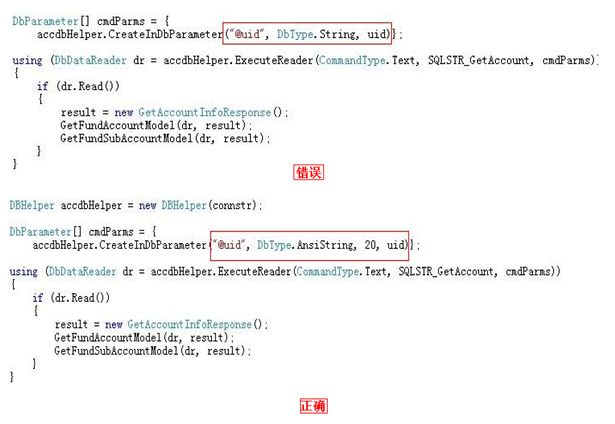
看了上面这两个图,我想我不用解释说明,大家都应该已经清楚了吧。
如果数据库字段类型为VARCHAR,在应用里面最好类型指定为AnsiString并明确指定其长度
如果数据库字段类型为CHAR,在应用里面最好类型指定为AnsiStringFixedLength并明确指定其长度
如果数据库字段类型为NVARCHAR,在应用里面最好类型指定为String并明确指定其长度
参数化查询
以下方式可以对查询SQL进行参数化:


限制JOIN个数
限制IN子句中条件个数
尽量避免大事务操作
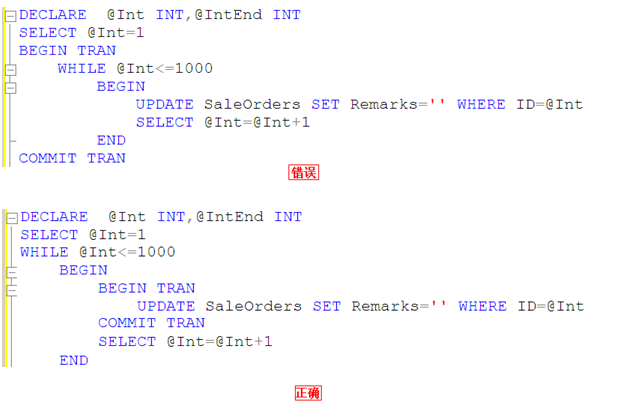
关闭影响的行计数信息返回
在SQL语句中显示设置Set Nocount On,取消影响的行计数信息返回,减少网络流量
除非必要,尽量让所有的select语句都必须加上NOLOCK
指定允许脏读。不发布共享锁来阻止其他事务修改当前事务读取的数据,其他事务设 置的排他锁不会阻碍当前事务读取锁定数据。允许脏读可能产生较多的并发操作,但其代价是读取以后会被其他事务回滚的数据修改。这可能会使您的事务出错,向 用户显示从未提交过的数据,或者导致用户两次看到记录(或根本看不到记录)
使用UNION ALL替换UNION
UNION会对SQL结果集去重排序,增加CPU、内存等消耗
查询大量数据使用分页或TOP
合理限制记录返回数,避免IO、网络带宽出现瓶颈
递归查询层次限制
使用 MAXRECURSION 来防止不合理的递归 CTE 进入无限循环
临时表与表变量
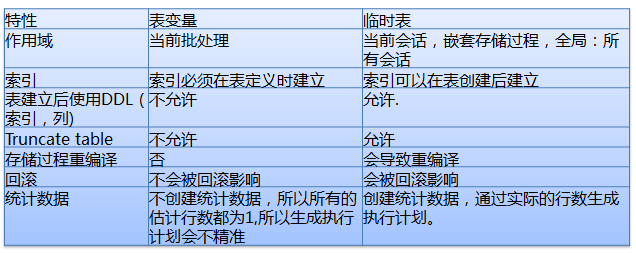
使用本地变量选择中庸执行计划
在存储过程或查询中,访问了一张数据分布很不平均的表格,这样往往会让存储过程或查询使用了次优甚至于较差的执行计划上,造成High CPU及大量IO Read等问题,使用本地变量防止走错执行计划。
采用本地变量的方式,SQL在编译的时候是不知道这个本地变量的值,这时候SQL会根据表格里数据的一般分布,“猜测”一个返回值。不管用户在调用存储过程或语句的时候代入的变量值是多少,生成的计划都是一样的。这样的计划一般会比较中庸一些,不一定是最优的计划,但一般也不会是最差的计划
Estimated Rows =(Total Rows * 30)/100
Estimated Rows = Density * Total Rows
尽量避免使用OR运算符
对于OR运算符,通常会使用全表扫描,考虑分解成多个查询用UNION/UNION ALL来实现,这里要确认查询能走到索引并返回较少的结果集
增加事务异常处理机制
输出列使用二段式命名格式
二段式命名格式:表名.字段名
有JOIN关系的TSQL,字段必须指明字段是属于哪个表的,否则未来表结构变更后,有可能发生Ambiguous column name的程序兼容错误
架构设计
读写分离
Schema解耦
禁止跨库JOIN
数据生命周期
根据数据的使用频繁度,对大表定期分库归档
主库/归档库物理分离
日志类型的表应分区或分表
对于大的表格要进行分区,分区操作将表和索引分在多个分区,通过分区切换能够快速实现新旧分区替换,加快数据清理速度,大幅减少IO资源消耗
频繁写入的表,需要分区或分表
自增长与Latch Lock
闩锁是sql Server自己内部申请和控制,用户没有办法来干预,用来保证内存里面数据结构的一致性,锁级别是页级锁