The article is from Microsoft.
Stop what you’re doing and text ten of your colleagues. Ask them to define the term “Cloud Native”. Good chance you’ll get ten different answers.
Cloud native is all about changing the way you think about constructing critical business systems.
Cloud-native systems are designed to embrace rapid change, large scale, and resilience.
The Cloud Native Computing Foundation provides an official definition:
Cloud-native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
Applications have become increasingly complex with users demanding more and more. Users expect rapid responsiveness, innovative features, and zero downtime. Performance problems, recurring errors, and the inability to move fast are no longer acceptable. They’ll easily move to your competitor.
Cloud native is about speed and agility. Business systems are evolving from enabling business capabilities to being weapons of strategic transformation that accelerate business velocity and growth. It’s imperative to get ideas to market immediately.
Here are some companies who have implemented these techniques. Think about the speed, agility, and scalability they’ve achieved.
| Company | Experience |
|---|---|
| Netflix | Has 600+ services in production. Deploys hundred times per day. |
| Uber | Has 1,000+ services in production. Deploys several thousand times each week. |
| Has 3,000+ services in production. Deploys 1,000 times a day. |
As you can see, Netflix, Uber, and WeChat expose systems that consist of hundreds of independent microservices. This architectural style enables them to rapidly respond to market conditions. They can instantaneously update small areas of a live, complex application, and individually scale those areas as needed.
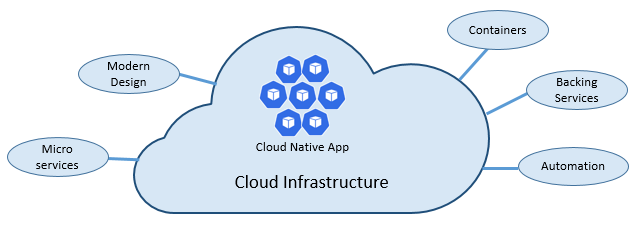
The speed and agility of cloud native come about from a number of factors. Foremost is cloud infrastructure. Five additional foundational pillars shown in Figure 1-3 also provide the bedrock for cloud-native systems.