In almost all .NET applications you encounter lot of boilerplate code which although has pretty standard implementation but is quite important from implementation point of view. Some common examples are overridden ToString, Equals method for you model classes. Or implementing IDisposable or INotifyPropertyChanged. In all these examples most of the code is pretty standard.
One of the ways of automating this code is to automatically inject this in your generated MSIL (which stands for Microsoft intermediate language).This process of injecting code post compilation directly into generated intermediate language is known as .NET assembly weaving or IL weaving (similar to byte code weaving in Java).
If you do this before compilation i.e. add source code lines before compilation it is known as Source code weaving.
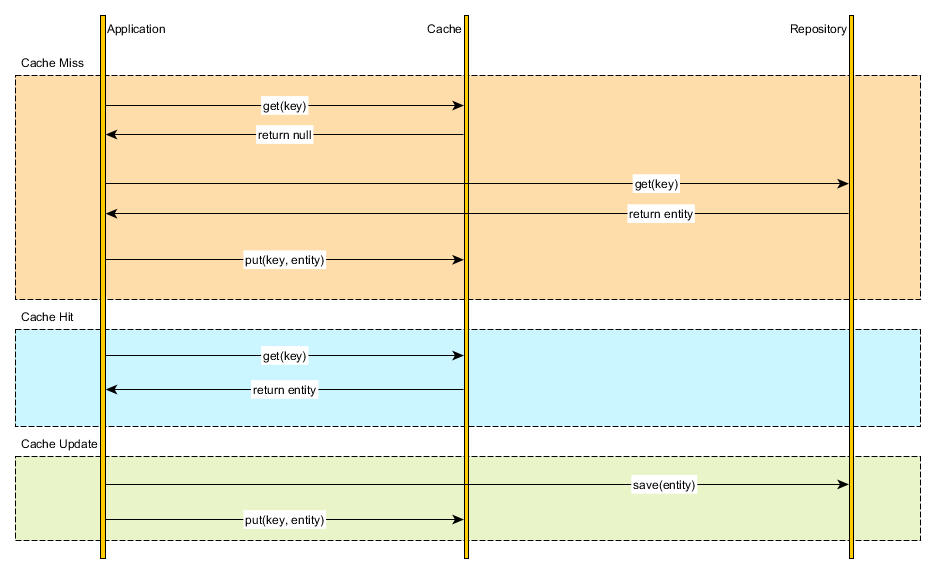
What is Fody and how it works.
Fody is an extensible library for weaving .NET assembly written by Simon Cropp. It adds post build task in MS build pipeline to manipulate generated IL. Usually this requires lot of plumbing code which is what fody provides. Fody provides extensible add-in model where anybody can use core fody package (providing basic code for adding post build task and manipulating IL) and create their own specific add-ins. E.g. Equals. Fody generates Equals and GetHashCode method implementation and ToString. Fody generates ToString implementation for your classes.
Below figure shows how the whole process works.
You can also use the same technique for implementing AOP, logging, profiling methods etc.
Fody uses Mono.Cecil which is a library for manipulating intermediate language and in usage feels quite similar to .NET reflection APIs. As far as IL manipulation goes Mono.Cecil seems like only game in the town. Chances are high that if you have used plug-in for IL manipulation they would be using Mono.Cecil internally. Continue reading “What’s FodyWeaver”