Load data on demand into a cache from a data store. This can improve performance and also helps to maintain consistency between data held in the cache and data in the underlying data store.
Context and problem
Applications use a cache to improve repeated access to information held in a data store. However, it’s impractical to expect that cached data will always be completely consistent with the data in the data store. Applications should implement a strategy that helps to ensure that the data in the cache is as up-to-date as possible, but can also detect and handle situations that arise when the data in the cache has become stale.
Solution
Many commercial caching systems provide read-through and write-through/write-behind operations. In these systems, an application retrieves data by referencing the cache. If the data isn’t in the cache, it’s retrieved from the data store and added to the cache. Any modifications to data held in the cache are automatically written back to the data store as well.
For caches that don’t provide this functionality, it’s the responsibility of the applications that use the cache to maintain the data.
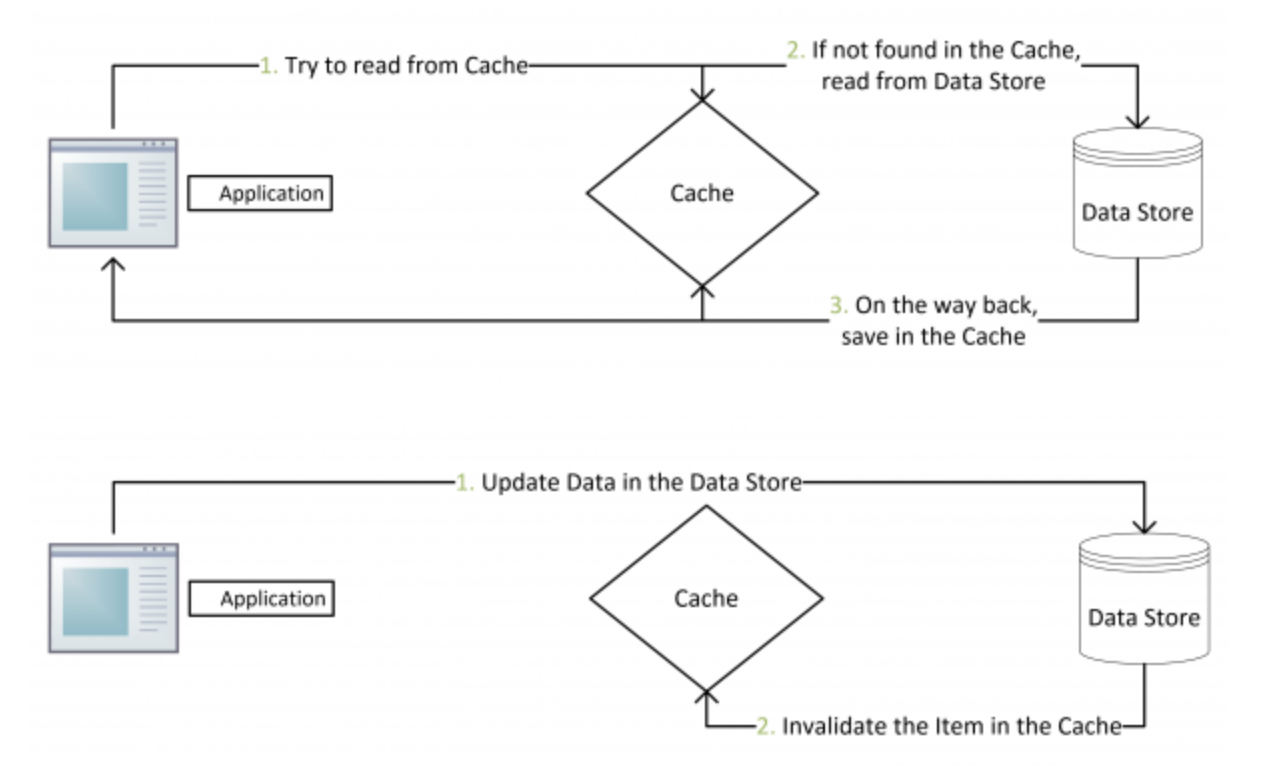
An application can emulate the functionality of read-through caching by implementing the cache-aside strategy. This strategy loads data into the cache on demand. The figure illustrates using the Cache-Aside pattern to store data in the cache.
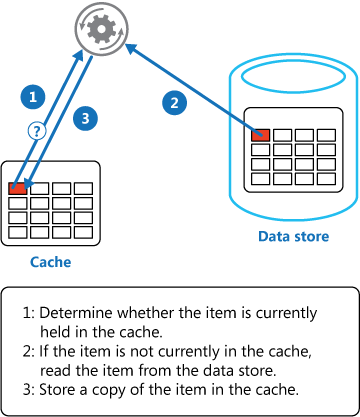
If an application updates information, it can follow the write-through strategy by making the modification to the data store, and by invalidating the corresponding item in the cache.
When the item is next required, using the cache-aside strategy will cause the updated data to be retrieved from the data store and added back into the cache. Continue reading “Cache-Aside pattern”